Hereditas(Beijing) ›› 2020, Vol. 42 ›› Issue (7): 691-702.doi: 10.16288/j.yczz.20-022
• Research Article • Previous Articles Next Articles
Comprehensive re-annotation of protein-coding genes for prokaryotic genomes by Z-curve and similarity-based methods
Shuo Liu1, Zhi Zeng1, Fancai Zeng2, Mengze Du2( )
)
- 1. School of Life Science and Technology, University of Electronic Science and Technology of China, Chengdu 611731, China
2. Department of Biochemistry and Molecular Biology, School of Basic Medicine, Southwest Medical University, Luzhou 646000,China
-
Received:2020-02-20Revised:2020-05-11Online:2020-07-20Published:2020-06-01 -
Contact:Du Mengze E-mail:du_mengze@foxmail.com -
Supported by:Supported by Science Strength Improvement Plan of University of Electronic Science and Technology of China No(Y0301902610100202)
Cite this article
Shuo Liu, Zhi Zeng, Fancai Zeng, Mengze Du. Comprehensive re-annotation of protein-coding genes for prokaryotic genomes by Z-curve and similarity-based methods[J]. Hereditas(Beijing), 2020, 42(7): 691-702.
share this article
Add to citation manager EndNote|Reference Manager|ProCite|BibTeX|RefWorks
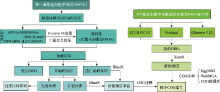
Fig. 1
The pipeline for re-annotation"
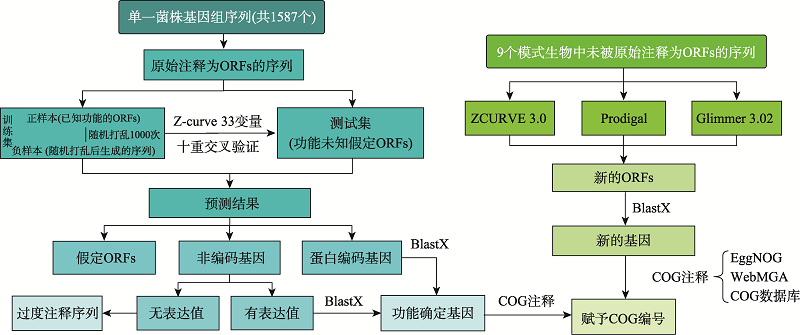
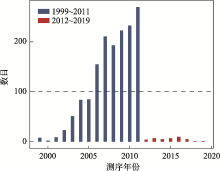
Fig. 2
The distribution of sequencing time for 1587 genomes"
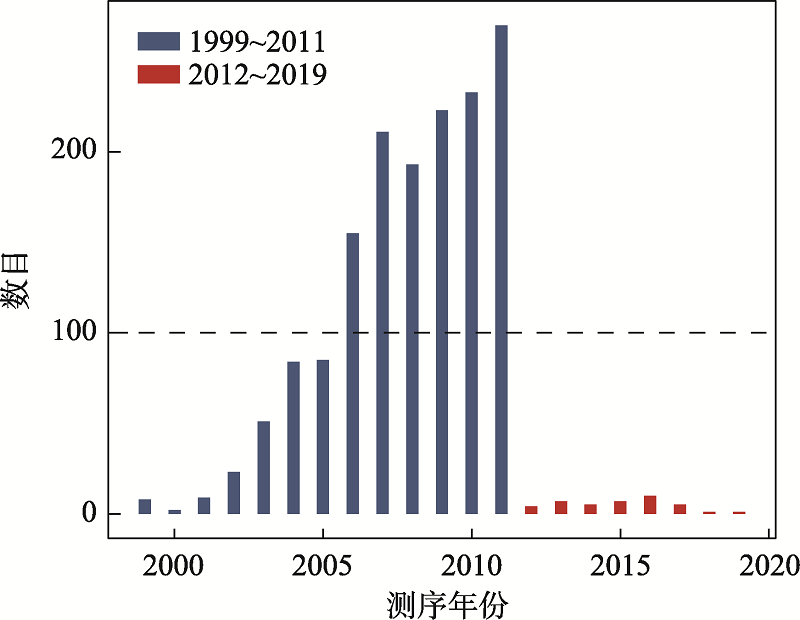
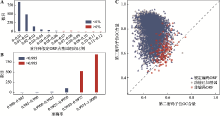
Fig. 3
The numbers of genomes according to ratio of hypothetical ORFs and accuracy for recognizing non-coding ORFs, and the GC contents of two codon positions of three types of sequences of B. japonicum USDA 110"
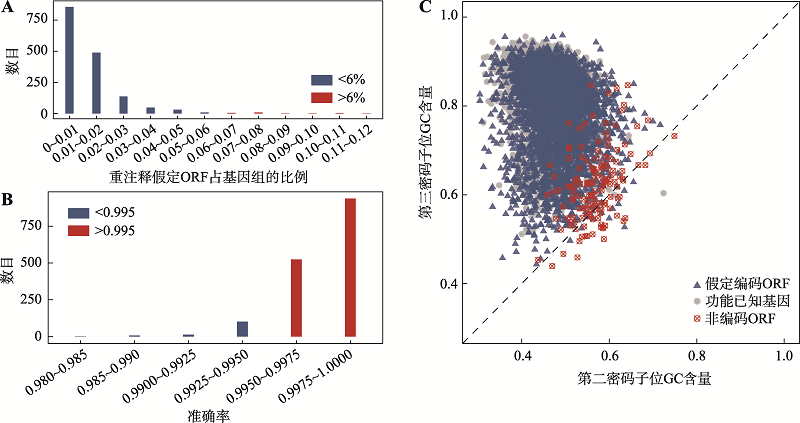
Table 1
The information of genomes with recognized over-annotated ORFs of more than 20"
| 菌株 | NC序列号 | 数量 | 菌株 | NC序列号 | 数量 |
|---|---|---|---|---|---|
| 慢性型大豆根瘤菌(B. japonicum USDA 110) | NC_004463 | 147 | 金黄色葡萄球菌 (S. aureus subsp. Aureus MW2) | NC_003923 | 36 |
| 哈氏弧菌(Vibrio harveyi ATCC BAA-1116) | NC_009784 | 133 | 黑海甲烷袋状菌 (Methanoculleus marisnigri JR1) | NC_009051 | 34 |
| 大肠杆菌(E. coli CFT073) | NC_004431 | 119 | 双叶钩端螺旋体血清型Patoc菌株 (Leptospira biflexa serovar Patoc strain 'Patoc 1) | NC_010602 | 34 |
| 织片草螺菌 (Herbaspirillum seropedicae SmR1) | NC_014323 | 109 | 拟杆菌属 (Bacteroides salanitronis DSM 18170) | NC_015164 | 34 |
| 结核分枝杆菌 (Mycobacterium tuberculosis CDC1551) | NC_002755 | 98 | 巴尔通体杆菌(Bartonella clarridgeiae 73) | NC_014932 | 33 |
| 多形类杆菌 (Bacteroides thetaiotaomicron VPI-5482) | NC_004663 | 84 | 梅毒螺旋体梅毒亚种 (Treponema pallidum subsp. pallidum SS14) | NC_010741 | 32 |
| 鞘脂菌(Sphingobium japonicum UT26S) | NC_014006 | 80 | 梅毒螺旋体 (Treponema paraluiscuniculi Cuniculi A) | NC_015714 | 32 |
| 生丝微菌属(Hyphomicrobium sp. MC1) | NC_015717 | 70 | 鼠疫杆菌(Yersinia pestis CO92) | NC_003143 | 31 |
| 长双歧杆菌(B. longum NCC2705) | NC_004307 | 69 | 台湾贪铜菌 (Cupriavidus taiwanensis LMG 19424) | NC_010528 | 31 |
| 大肠杆菌(E. coli O157:H7 str. Sakai) | NC_002695 | 55 | 噬纤维素菌属 (Cellulophaga algicola DSM 14237) | NC_014934 | 31 |
| 哈维弧菌(V. harveyi ATCC BAA-1116) | NC_009783 | 53 | 结核分枝杆菌(M. tuberculosis H37Rv) | NC_000962 | 30 |
| 溶血葡萄球菌(S. haemolyticus JCSC1435) | NC_007168 | 51 | 沙漠自然球菌(Deinococcus deserti VCD115) | NC_012526 | 30 |
| 缓纤维梭菌 (Clostridium lentocellum DSM 5427) | NC_015275 | 51 | 溃疡拟杆菌(Bacteroides helcogenes P 36-108) | NC_014933 | 27 |
| 表皮葡萄球菌(S. epidermidis RP62A) | NC_002976 | 47 | 金黄色葡萄球菌 (S. aureus subsp. Aureus Mu50) | NC_002758 | 26 |
| 鼠疫杆菌(Y. pestis KIM10+) | NC_004088 | 46 | 金黄色葡萄球菌 (S. aureus subsp. Aureus N315) | NC_002745 | 25 |
| 海单孢菌属 (Marinomonas mediterranea MMB-1) | NC_015276 | 43 | 内脏臭气杆菌 (Odoribacter splanchnicus DSM 20712) | NC_015160 | 25 |
| 红球菌(Rhodococcus jostii RHA1) | NC_008268 | 40 | 嗜热盐碱细菌 (Natranaerobius thermophilus JW/NM-WN-LF) | NC_010718 | 23 |
| 大肠杆菌(E. coli O157:H7 str. EDL933) | NC_002655 | 39 | 圆柱杆菌(Teredinibacter turnerae T7901) | NC_012997 | 23 |
| 固氮密螺旋体(T. azotonutricium ZAS-9) | NC_015577 | 39 | 盐孢菌属(Salinispora tropica CNB-440) | NC_009380 | 20 |
| 白蚁塞巴鲁德氏菌 (Sebaldella termitidis ATCC 33386) | NC_013517 | 38 | 巴西浮霉状菌 (Planctomyces brasiliensis DSM 5305) | NC_015174 | 20 |
| 金黄色葡萄球菌(S. aureus subsp.COL) | NC_002951 | 37 | 苜蓿根瘤菌(Sinorhizobium meliloti AK83) | NC_015590 | 20 |
| 肺炎衣原体 (Chlamydophila pneumoniae AR39) | NC_002179 | 36 |
Table 2
The information of genomes with 20 more hypothetical ORFs with annotated function"
| 菌株 | NC序列号 | 数量 | 菌株 | NC序列号 | 数量 |
|---|---|---|---|---|---|
| 大肠杆菌(E. coli O111:H-str. 11128) | NC_013364 | 80 | 炭疽芽孢杆菌(B. anthracis str. CDC 684) | NC_012581 | 23 |
| 肠道沙门氏菌(S. enterica subsp. enterica serovar Paratyphi B str. SPB7) | NC_010102 | 64 | 肠道沙门氏菌(S. enterica subsp. enterica serovar Paratyphi C strain RKS4594) | NC_012125 | 23 |
| 鲍氏志贺菌(Shigella boydii CDC 3083-94) | NC_010658 | 52 | 金黄色葡萄球菌(S. aureus subsp. aureus MW2) | NC_003923 | 23 |
| 肠道沙门氏菌(S. enterica subsp. arizonae serovar 62:z4, z23:- str. RSK2980) | NC_010067 | 45 | 蜡状芽孢杆菌(Bacillus cereus ATCC 10987) | NC_003909 | 22 |
| 枯草芽孢杆菌(B. subtilis subsp. subtilis str. 168) | NC_000964 | 42 | 大肠杆菌(E. coli O26:H11 str. 11368) | NC_013361 | 22 |
| 鼠李糖乳杆菌(Lactobacillus rhamnosus Lc 705) | NC_013199 | 38 | 肺炎链球菌(Streptococcus pneumoniae P1031) | NC_012467 | 22 |
| 鼠李糖乳杆菌(L. rhamnosus GG) | NC_013198 | 36 | 金黄色葡萄球菌(S. aureus subsp. aureus Mu3) | NC_009782 | 21 |
| 肠道沙门氏菌(S. enterica subsp. enterica serovar Paratyphi A str. AKU_12601) | NC_011147 | 35 | 金黄色葡萄球菌(S. aureus subsp. aureus JH9) | NC_009487 | 21 |
| 大肠杆菌(E. coli O157:H7 str. Sakai) | NC_002695 | 34 | 结核分枝杆菌(M. tuberculosis CDC1551) | NC_002755 | 20 |
| 大肠杆菌(E. coli O157:H7 str. EDL933) | NC_002655 | 30 | 炭疽芽孢杆菌(B. anthracis str. A0248) | NC_012659 | 20 |
| 肠道沙门氏菌(S. enterica subsp. enterica serovar Paratyphi A str. ATCC 9150) | NC_006511 | 30 | 大肠杆菌(E. coli O157:H7 str. EC4115) | NC_011353 | 20 |
| 大肠杆菌(E. coli SE11) | NC_011415 | 28 | 炭疽芽孢杆菌(B. anthracis str. Ames) | NC_003997 | 20 |
| 大肠杆菌(E. coli ED1a) | NC_011745 | 27 | 哈维氏弧菌(V. harveyi ATCC BAA-1116) | NC_009783 | 20 |
| 大肠杆菌(E. coli UTI89) | NC_007946 | 26 | 结核分枝杆菌(M. tuberculosis KZN 1435) | NC_012943 | 20 |
| 枯草芽孢杆菌(B. subtilis BSn5) | NC_014976 | 25 | 大肠杆菌(E. coli O55:H7 str. CB9615) | NC_013941 | 20 |
| 肠道沙门氏菌 (S. enterica subsp. enterica serovar Typhi str. Ty2) | NC_004631 | 25 | 牛型分枝杆菌 (Mycobacterium bovis AF2122/97) | NC_002945 | 20 |
| 大肠杆菌(E. coli CFT073) | NC_004431 | 23 |
Table 3
Newly annotated genes of E.coli str. K-12 substr. MG1655 under loose threshold"
| 正/负链(在基因组上位置) | 同源序列来源 | 功能 | E值 | 覆盖度 (%) | 一致性 (%) |
|---|---|---|---|---|---|
| 负链(190551~191603) | 肠道沙门菌 (S. enterica subsp. enterica) | 亮氨酸操纵子先导肽 (leu operon leader peptide) | 8e-139 | 79 | 74.01 |
| 负链(2228549~2228758) | 志贺氏菌属(Shigella) | 多药耐药外膜蛋白MdtQ (multidrug resistance outer membrane protein MdtQ) | 1e-27 | 72 | 100 |
| 负链(4322661~4323281) | 志贺氏菌属(Shigella) | Pn转运体膜通道蛋白组分(membrane channel protein component of Pn transporter) | 4e-108 | 77 | 98.74 |
| 负链(4500432~4500791) | 猪布鲁氏杆菌(Brucella suis) | 磷酸乙醇胺转移酶(MULTISPECIES: phosphoethanolamine transferase) | 3e-45 | 69 | 91.57 |
| 正链(1465410~1467950) | 宋内志贺菌(Shigella sonnei) | 包含蛋白质的自转运体结构域 (autotransporter domain-containing protein) | 0.0 | 74 | 87.03 |
| 正链(1470858~1474013) | 福氏志贺氏菌 (Shigella flexneri) | 自转运体外膜β管(MULTISPECIES: autotransporter outer membrane beta-barrel) | 0.0 | 76 | 100 |
| 正链(2070501~2071211) | 双歧杆菌 (Bifidobacterium longum) | GTPase家族蛋白(GTPase family protein) | 4e-129 | 77 | 99.45 |
| 正链(3993850~3994335) | 痢疾志贺氏菌 (Shigella dysenteriae 1617) | CyaX蛋白(CyaX protein) | 9e-67 | 63 | 96.12 |
| 负链(4506626~4506883) | 红树杆菌属 (Mangrovibacter plantisponsor) | 表皮粘着蛋白E (surface-adhesin protein E) | 1e-28 | 98 | 60 |
Table 4
The names of nine strains, NC number, genome size, gene numbers and number of new genes"
| 菌株 | NC序列号 | 基因组大小(bp) | 基因总数 | 新基因的数目 |
|---|---|---|---|---|
| 枯草芽孢杆菌(B. subtilis subsp. subtilis str. 168) | NC_000964 | 4215606 | 4175 | 52 |
| 金黄色葡萄球菌(S. aureus subsp. aureus NCTC 8325) | NC_007795 | 2821361 | 2767 | 61 |
| 酿脓链球菌(S. pyogenes SF370) | NC_002737 | 1852441 | 1696 | 104 |
| 流感嗜血杆菌(H. influenzae Rd KW20) | NC_000907 | 1830138 | 1610 | 123 |
| 嗜酸氧化亚铁硫杆菌(A. ferrooxidans ATCC 23270) | NC_011761 | 2982397 | 3147 | 143 |
| 大肠杆菌(E. coli str. K-12 substr. MG1655) | NC_000913 | 4641652 | 4140 | 246 |
| 脑膜炎奈瑟球菌(N. meningitidis MC58) | NC_003112 | 2272360 | 1953 | 279 |
| 炭疽芽孢杆菌(B. anthracis str. Ames) | NC_003997 | 5227293 | 5039 | 418 |
| 肠道沙门氏菌(S. enterica subsp. enterica serovar Typhi str. CT18) | NC_003198 | 4809037 | 4111 | 577 |
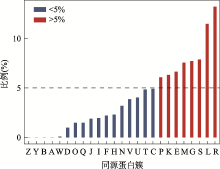
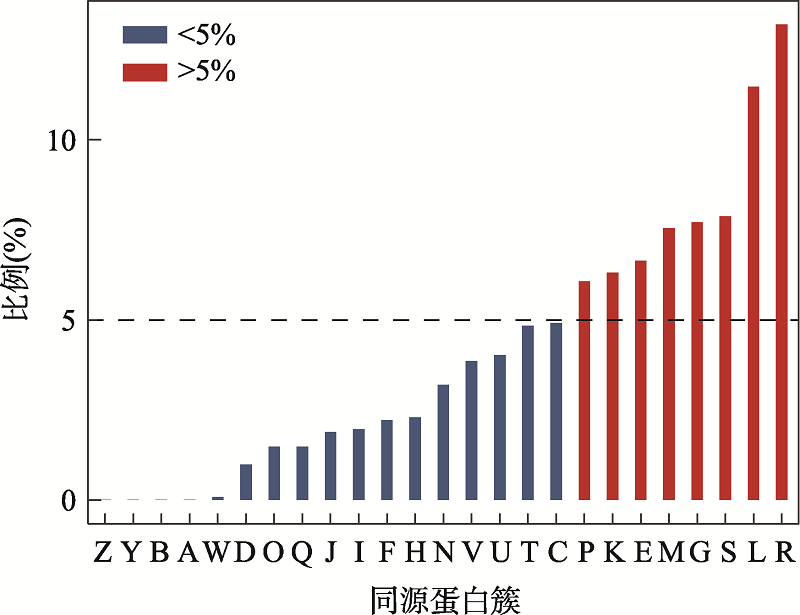
Fig. 4
The ratio of the newly recognized genes of certain COG to all new genes"

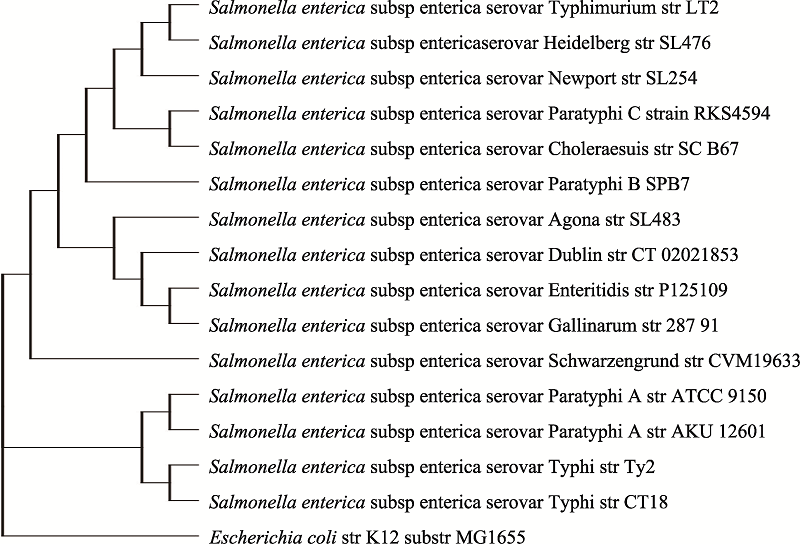
Supplementary Fig. 1
The phylogenetic tree of different serological types of S. enterica sub-species"
| [1] | Mørk S, Holmes I . Evaluating bacterial gene-finding HMM structures as probabilistic logic programs. Bioinformatics, 2012,28(5):636-642. |
| [2] | Warren AS, Archuleta J, Feng WC, Setubal JC . Missing genes in the annotation of prokaryotic genomes. BMC Bioinformatics, 2010,11(1):131. |
| [3] | Salzberg SL . Next-generation genome annotation: we still struggle to get it right. Genome Biol, 2019,20(1):92. |
| [4] | Breitwieser FP, Pertea M, Zimin AV, Salzberg SL . Human contamination in bacterial genomes has created thousands of spurious proteins. Genome Res, 2019,29(6):954-960. |
| [5] | Fleischmann RD, Adams MD, White O, Clayton RA, Kirkness EF, Kerlavage AR, Bult CJ, Tomb JF, Dougherty BA, Merrick JM, Mckenney K, Sutton G, FitzHugh W,Fields C,Gocayne JD,Scott J,Shirley R,Liu LL,Glodek A,Kelley JM,Weidman JF,Phillips CA,Spriggs T,Hedblom E,Cotton MD,Utterback TR,Hanna MC,Nguyen DT,Saudek DM,Brandon RC,Fine LD,Fritchman JL,Fuhrmann JL,Geoghagen NSM,Gnehm CL,McDonald LA,Small KV,Fraser CM,Smith HO,Venter JC. Whole-genome random sequencing and assembly of Haemophilus influenzae Rd. Science, 1995,269(5223):496-512. |
| [6] | Benson DA, Karsch-Mizrachi I, Lipman DJ, Ostell J, Sayers EW . Genbank. Nucleic Acids Res, 2009,37(Database issue):D26-D31. |
| [7] | Yu JF, Xiao K, Jiang DK, Guo J, Wang JH, Sun X . An Integrative method for identifying the over-annotated protein-coding genes in microbial genomes. DNA Res, 2011,18(6):435-449. |
| [8] | Hua ZG, Lin Y, Yuan YZ, Yang DC, Wei W, Guo FB . ZCURVE 3.0: identify prokaryotic genes with higher accuracy as well as automatically and accurately select essential genes. Nucleic Acids Res, 2015,43(W1):W85-W90. |
| [9] | Zickmann F, Renard BY . IPred-integrating ab initio and evidence based gene predictions to improve prediction accuracy. BMC Genomics, 2015,16(1):134. |
| [10] | Keilwagen J, Wenk M, Erickson JL, Schattat MH, Grau J, Hartung F . Using intron position conservation for homology-based gene prediction. Nucleic Acids Res, 2016,44(9):e89. |
| [11] | Besemer J, Lomsadze A, Borodovsky M . GeneMarkS:a self-training method for prediction of gene starts in microbial genomes. Implications for finding sequence motifs in regulatory regions. Nucleic Acids Res, 2001,29(12):2607-2618. |
| [12] | Kelley DR, Liu B, Delcher AL, Pop M, Salzberg SL . Gene prediction with Glimmer for metagenomic sequences augmented by classification and clustering. Nucleic Acids Res, 2012,40(1):e9. |
| [13] | Larsen TS, Krogh A . EasyGene-a prokaryotic gene finder that ranks ORFs by statistical significance. BMC Bioinformatics, 2003,4(1):21. |
| [14] | Guo FB, Ou HY, Zhang CT . ZCURVE: a new system for recognizing protein-coding genes in bacterial and archaeal genomes. Nucleic Acids Res, 2003,31(6):1780-1789. |
| [15] | Du MZ, Guo FB, Chen YY . Gene re-annotation in genome of the extremophile Pyrobaculum Aerophilum by using bioinformatics methods. J Biomol Struct Dyn, 2011,29(2):391-401. |
| [16] | Guo FB, Xiong LF, Teng JL, Yuen KY, Lau SK, Woo PC . Re-annotation of protein-coding genes in 10 complete genomes of Neisseriaceae family by combining similarity- based and composition-based methods. DNA Res, 2013,20(3):273-286. |
| [17] | Lei Y, Kang SK, Gao JX, Jia XS, Chen LL . Improved annotation of a plant pathogen genome Xanthomonas oryzae pv. oryzae PXO99A. J Biomol Struct Dyn, 2013,31(3):342-350. |
| [18] | Mao Y, Yang X, Liu Y, Yan Y, Du Z, Han Y, Song Y, Zhou L, Cui Y, Yang R . Reannotation of Yersinia pestis strain 91001 Based on Omics Data. Am J Trop Med Hyg, 2016,95(3):562-570. |
| [19] | Pfeiffer F, Bagyan I, Alfaro‐Espinoza G,Zamora‐Lagos MA,Habermann B,Marin‐Sanguino A,Oesterhelt D,Kunte HJ. Revision and reannotation of the Halomonas elongata DSM 2581T genome. MicrobiologyOpen, 2017,6(4):e00465. |
| [20] | Delcher AL, Bratke KA, Powers EC, Salzberg SL . Identifying bacterial genes and endosymbiont DNA with Glimmer. Bioinformatics, 2007,23(6):673-679. |
| [21] | Zhang R, Zhang CT . A Brief Review:The Z-curve theory and its application in genome analysis. Curr Genomics, 2014,15(2):78-94. |
| [22] | Weiss MC, Sousa FL, Mrnjavac N, Neukirchen S, Roettger M, Nelson-Sathi S, Martin WF . The physiology and habitat of the last universal common ancestor. Nat Microbiol, 2016,1(9):16116. |
| [23] | Hyatt D, Chen GL, Locascio PF, Land ML, Larimer FW, Hauser LJ . Prodigal: prokaryotic gene recognition and translation initiation site identification. BMC Bioinformatics, 2010,11(1):119. |
| [24] | Barrett TT, Troup DB, Wilhite SE, Ledoux P, Rudnev D, Evangelista C, Kim IF, Soboleva A, Tomashevsky M, Marshall KA, Phillippy KH, Sherman PM, Muertter RN, Edgar R . NCBI GEO: archive for high-throughput functional genomic data. Nucleic Acids Res, 2009,37(Database issue):D885-D890. |
| [25] | Wang M, Weiss M, Simonovic M, Haertinger G, Schrimpf SP, Hengartner MO,von Mering C. PaxDb, a database of protein abundance averages across all three domains of life. Mol Cell Proteomics, 2012,11(8):492-500. |
| [26] | McGinnis S, Madden TL . BLAST: at the core of a powerful and diverse set of sequence analysis tools. Nuleic Acids Res, 2004,32(Suppl.2):W20-W25. |
| [27] | Wood DE, Lin H, Levy-Moonshine A, Swaminathan R, Chang YC, Anton BP, Osmani L, Steffen M, Kasif S, Salzberg SL . Thousands of missed genes found in bacterial genomes and their analysis with COMBREX. Biol Direct, 2012,7(1):37. |
| [28] | Huerta-Cepas J, Szklarczyk D, Forslund K, Cook H, Heller D, Walker MC, Rattei T, Mende DR, Sunagawa S, Kuhn M, Jensen LJ, Mering CV, Bork P. eggNOG 4.5: a hierarchical orthology framework with improved functional annotations for eukaryotic, prokaryotic and viral sequences. Nucleic Acids Res, 2016,44(Database issue):D286-D293. |
| [29] | Wu ST, Zhu ZW, Fu LM, Niu BF, Li WZ . WebMGA: a customizable web server for fast metagenomic sequence analysis. BMC Genomics, 2011,12(1):444. |
| [30] | Tatusov RL, Galperin MY, Natale DA, Koonin EV . The COG database: a tool for genome-scale analysis of protein functions and evolution. Nucleic Acids Res, 2000,28(1):33-36. |
| [31] | Qi J, Luo H, Hao BL . CVTree: a phylogenetic tree reconstruction tool based on whole genomes. Nucleic Acids Res, 2004,32:W45-W47. |
| [32] | Hockenbery D, Nuñez G, Milliman C, Schreiber RD, Korsmeyer SJ . Bcl-2 is an inner mitochondrial membrane protein that blocks programmed cell death. Nature, 1990,348(6299):334-336. |
| [33] | Liu WQ, Feng Y, Wang Y, Zou QH, Chen F, Guo JT, Peng YH, Jin Y, Li YG, Hu SN, Johnson RN, Liu GR, Liu SL . Salmonella paratyphi C: Genetic divergence from Salmonella choleraesuis and pathogenic convergence with Salmonella typhi. PLoS One, 2009,4(2):e4510. |
| [34] | Vankuren NW, Long M . Gene duplicates resolving sexual conflict rapidly evolved essential gametogenesis functions. Nat Ecol Evol, 2018,2(4):705-712. |
| [35] | Minor LL, Bockemühl J . 1987 supplement (no.31) to the schema of Kauffmann-White. Ann Inst Pasteur Microbiol, 1988,139(3):331-335. |
| [36] | Dwyer DJ, Belenky PA, Yang JH, Macdonald IC, Martell JD, Takahashi N, Chan CT,lobritz MA,Braff D,Schwarz EG,Ye JD,Pati M,Vercruysse M,Ralifo PS,Allison KR,Khalil AS,Ting AY,Walker GC,Collins JJ. Antibiotics induce redox-related physiological alterations as part of their lethality. Proc Natl Acad Sci USA, 2014,111(20):E2100-E2109. |
| [37] | Hadjeras L, Poljak L, Bouvier M, Morin-Ogier Q, Canal l,Cocaign-Bousquet M,Girbal L,Carpousis AJ. Detachment of the RNA degradosome from the inner membrane of Escherichia coli results in a global slowdown of mRNA degradation, proteolysis of RNase E and increased turnover of ribosome-free transcripts. Mol Microbiol, 2019,111(6):1715-1731. |
| [38] | Kim S, Yu Z, Kil RM, Lee M . Deep learning of support vector machines with class probability output networks. Neural Netw, 2015,64:19-28. |
| [39] | Guo FB . The distribution patterns of bases of protein- coding genes, non-coding ORFs, and intergenic sequences in Pseudomonas aeruginosa PA01 genome and its implication. J Biomol Struct Dyn, 2007,25(2):127-133. |
| [40] | Uyar B, Yusuf D, Wurmus R, Rajewsky N, Ohler U, Akalin A . RCAS: an RNA centric annotation system for transcriptome-wide regions of interest. Nucleic Acids Res, 2017,45(10):e91. |
| [41] | Huang Y, Liu Q, Chi LJ, Shi CM, Wu Z, Hu M, Shi H, Chen H . Application of BIG-Annotator in the genome sequencing data functional annotation and genetic diagnosis. Hereditas(Beijing), 2018,40(11):1015-1023. |
| 黄莹, 刘琪, 池连江, 石承民, 吴祯, 胡敏, 石宏, 陈华 . BIG-Annotator: 基因组测序数据高效功能注释及其在遗传诊断中的应用. 遗传, 2018,40(11):1015-1023. | |
| [42] | Bick JT, Zeng SQ, Robinson MD, Ulbrich SE, Bauersachs S . Mammalian Annotation Database for improved annotation and functional classification of Omics datasets from less well-annotated organisms. Database(Oxford), 2019,2019:1-16. |
| [43] | Ravindran SP, Lüneburg J, Gottschlich L, Tams V, Cordellier M . Daphnia stressor database: Taking advantage of a decade of Daphnia ‘-omics’ data for gene annotation. Sci Rep, 2019,9(1):11135. |
| [1] | Zhongling Wen, Minkai Yang, Xingyu Chen, Chenyu Hao, Ran Ren, Shujuan Chu, Hongwei Han, Hongyan Lin, Guihua Lu, Jinliang Qi, Yonghua Yang. Bacterial composition, function and the enrichment of plant growth promoting rhizobacteria (PGPR) in differential rhizosphere compartments of Al-tolerant soybean in acidic soil [J]. Hereditas(Beijing), 2021, 43(5): 487-500. |
| [2] |
Jinyu Li, Shan Yang, Yujun Cui, Tao Wang, Yue Teng.
|
| [3] | Chao Yang, Ruifu Yang, Yujun Cui. Bacterial genome-wide association study: methodologies and applications [J]. Hereditas(Beijing), 2018, 40(1): 57-65. |
| [4] | Lingxian Yi,Yiyun Liu,Renjie Wu,Zisen Liang,Jian-Hua Liu. Research progress on the plasmid-mediated colistin resistance gene mcr-1 [J]. Hereditas(Beijing), 2017, 39(2): 110-126. |
| [5] | Xiaonan Pang, Xiao Hong, Xuan Wei, Xiwen Chen, Jia Liu, Defu Chen. Research progress in physicochemical characteristics of lactoferrin and its recombinant expression systems [J]. HEREDITAS(Beijing), 2015, 37(9): 873-884. |
| [6] | Zhifang Li, Zili Feng, Lihong Zhao, Yongqiang Shi, Hongjie Feng, Heqin Zhu. Effects of transgenic cotton expressing chitinase and glucanase genes on the diversity of soil bacterial community [J]. HEREDITAS(Beijing), 2015, 37(8): 821-827. |
| [7] | Longxiang Xie, Zhaoxiao Yu, Siyao Guo, Ping Li, Abualgasim Elgaili Abdalla, Jianping Xie. The roles of epigenetics and protein post-translational modifications in bacterial antibiotic resistance [J]. HEREDITAS(Beijing), 2015, 37(8): 793-800. |
| [8] | Kai Xia, Xinle Liang, Yudong Li. Comparative genomics and evolutionary analysis of CRISPR loci in acetic acid bacteria [J]. HEREDITAS(Beijing), 2015, 37(12): 1242-1250. |
| [9] | YANG Xiao-Liang, BAI Da-Zhang, QIU Wei, DONG Hui-Qin, LI Da-Quan, CHEN Fang, MA Run-Lin, Hugh T Blair, GAO Jian-Feng. Screening of tissues pooled cDNA library using probes by restricted fragments of BAC positive clones of ovine MHC [J]. HEREDITAS, 2012, 34(7): 887-894. |
| [10] | XIAO Feng, LI Ren-Hui. Cyanobacterial genome transposable element mining and analysis based on 454 deep-sequencing data set [J]. HEREDITAS, 2011, 33(6): 654-660. |
| [11] | BANG Wen-Fang, LV Jian-Wei, LIN Xiao-Beng, HUANG Chi, DIAO Xin-Yan, WEN Ai-Gen, JIANG Hui-Fang. Differential expression of genes related to bacterial wilt resistance in peanut (Arachis hypogaea L.) [J]. HEREDITAS, 2011, 33(4): 389-396. |
| [12] | XIE Che-Chu, GU Hai-Yun, CHEN Ru-Hua. Regulation of chitinase genes expression in bacteria [J]. HEREDITAS, 2011, 33(10): 1029-1038. |
| [13] | XIE Zhao-Hui. The roles of RNA silencing in plant biotic stress [J]. HEREDITAS, 2010, 32(6): 561-570. |
| [14] | ZHANG Ju-Yong, HUANG Cheng-Feng, WANG Wei, XU An-Long, WANG Xi-Quan. Construction of genome BAC library for single Branchiostoma belcheri individual [J]. HEREDITAS, 2010, 32(1): 67-72. |
| [15] | REN Hong-Lin, XU Dan-Dan, QIAO Kun, CAI Ling, HUANG Wei-Bin, ZHANG Nai, WANG Ke-Jian. Construction of SSH library from haemocyte of variously colored abalone challenged with bacteria and differential expression analysis of macrophage expressed protein [J]. HEREDITAS, 2008, 30(8): 1043-1050. |
| Viewed | ||||||
|
Full text |
|
|||||
|
Abstract |
|
|||||

