
遗传 ›› 2026, Vol. 48 ›› Issue (7): 726-740.doi: 10.16288/j.yczz.25-261
王帅琪1,2( ), 王春年1,2, 张德琴2,3, 娄琳琳2,4, 班一婷2, 江丽2(), 李彩霞1,2()
), 王春年1,2, 张德琴2,3, 娄琳琳2,4, 班一婷2, 江丽2(), 李彩霞1,2()
收稿日期:2025-12-23
修回日期:2026-02-18
出版日期:2026-07-20
发布日期:2026-03-06
通讯作者:
江丽,博士,副主任法医师,研究方向:法医遗传学。E-mail: jl@mail.bnu.edu.cn;作者简介:王帅琪,硕士研究生,专业方向:生物物证。E-mail: qwert0019155@gmail.com
基金资助:
Shuaiqi Wang1,2(), Chunnian Wang1,2, Deqin Zhang2,3, Linlin Lou2,4, Yiting Ban2, Li Jiang2(), Caixia Li1,2()
Received:2025-12-23
Revised:2026-02-18
Published:2026-07-20
Online:2026-03-06
Supported by:摘要:
汉族人群具有复杂的遗传结构,不同地区人群存在一定程度的地域遗传差异,探究汉族人群的精细遗传结构,并构建高效的地域来源推断模型,对于揭示人群演化规律及实现精准祖源推断具有重要意义。然而当前针对国内汉族人群的祖源推断模型却较为缺乏。本研究旨在通过分析汉族人群高密度SNP数据,探索人群遗传结构与地理分布的关联,并基于机器学习算法构建地域来源推断模型,提升祖源推断技术对国内汉族人群的分辨力。研究选取来自中国8个省份的汉族人群全基因组SNP数据,通过连锁不平衡检验等进行质控并构建人群数据集,质控后共获得1,229份样本和208,193个SNP位点,首先应用主成分分析(principal component analysis,PCA)、ADMIXTURE聚类分析等方法进行遗传结构分析,结果表明不同地域的汉族存在一定程度的遗传结构差异,并据此将汉族人群划分为7个遗传分区。在此基础上,使用机器学习(machine learning,ML)算法,以PCA降维后主成分(principal component,PC)为输入特征,基于参考人群数据集5折交叉验证对比XGBoost(eXtreme gradient boosting)、随机森林(random forest,RF)和K近邻(K-nearest neighbors,KNN)等不同机器学习分类模型的预测性能,引入似然比(likelihood ratio,LR)方法作为评价指标,构建最优预测模型并在独立测试集中进行验证。结果表明,在参考集中,PCA-XGBoost模型预测性能最优,第1位预测准确率为87.66%,LR准确率为96.87%。在测试集中,PCA-XGBoost模型第1位预测准确率达到85%以上,LR准确率95%以上,表明该模型具有良好的泛化能力。综上,本研究开发的PCA-XGBoost预测模型兼具高效性、稳健性与高准确性,为群体遗传学及法医遗传学等相关研究提供了可靠的方法学工具。
王帅琪, 王春年, 张德琴, 娄琳琳, 班一婷, 江丽, 李彩霞. 基于机器学习的汉族人群地域来源推断模型[J]. 遗传, 2026, 48(7): 726-740.
Shuaiqi Wang, Chunnian Wang, Deqin Zhang, Linlin Lou, Yiting Ban, Li Jiang, Caixia Li. Machine learning-based geographical ancestry inference model for the Han Chinese population[J]. Hereditas(Beijing), 2026, 48(7): 726-740.
表1
样本信息"
| 群体信息 | 人群缩写 | 样本量 | 地理分区 | ChinaMAP遗传分区c) | WBBC遗传分区d) | |
|---|---|---|---|---|---|---|
| 参考集 | 测试集 | |||||
| 黑龙江汉族a) | HLJ | 123 | 30 | 东北 | 北方汉族 | 北方汉族 |
| 河北汉族a) | HEB | 123 | 30 | 华北 | ||
| 辽宁汉族b) | LN | / | 30 | 东北 | ||
| 山西汉族b) | SX | / | 30 | 华北 | ||
| 甘肃汉族a) | GS | 124 | 30 | 西北 | 西北汉族 | |
| 青海汉族b) | QH | / | 30 | 西北 | ||
| 江苏汉族a) | JS | 123 | 30 | 华东 | 东部汉族 | 中部汉族 |
| 上海汉族b) | SH | / | 30 | 华东 | ||
| 湖北汉族a) | HUB | 125 | 30 | 华中 | 中部汉族 | 南方汉族 |
| 云南汉族a) | YN | 124 | 30 | 西南 | 南方汉族 | |
| 贵州汉族b) | GZ | / | 30 | 西南 | ||
| 福建汉族a) | FJ | 123 | 30 | 华东 | 东南汉族 | |
| 广西汉族a) | GX | 124 | 30 | 华南 | 岭南汉族 | 岭南汉族 |
| 广东汉族b) | GD | / | 30 | 华南 | ||
附表1
样本测序方法及基本信息"
| 遗传分区 | 群体信息 | 人群缩写 | 样本量 | 来源参考集 | 测序方法 | ||||
|---|---|---|---|---|---|---|---|---|---|
| 参考集 | 测试集 | GSA | CGA | sequencing (5×) | sequencing (15×) | ||||
| 北方汉族 | 黑龙江汉族a) | HLJ | 123 | 30 | 本实验室 | 125 | 27 | 1 | / |
| 河北汉族a) | HEB | 123 | 30 | 本实验室 | 136 | 3 | 14 | / | |
| 辽宁汉族b) | LN | / | 30 | 本实验室 | 26 | 3 | / | 1 | |
| 山西汉族b) | SX | / | 30 | 本实验室 | 29 | 1 | / | / | |
| 西北汉族 | 甘肃汉族a) | GS | 124 | 30 | 本实验室 | 151 | 2 | / | 1 |
| 青海汉族b) | QH | / | 30 | 本实验室 | 11 | / | / | 19 | |
| 中部汉族 | 湖北汉族a) | HUB | 125 | 30 | 本实验室 | 116 | 39 | / | / |
| 东部汉族 | 江苏汉族a) | JS | 123 | 30 | 本实验室 | 149 | / | / | 4 |
| 上海汉族b) | SH | / | 30 | 本实验室 | 24 | 6 | / | / | |
| 西南汉族 | 云南汉族a) | YN | 124 | 30 | 本实验室 | 98 | 55 | 1 | / |
| 贵州汉族b) | GZ | / | 30 | 本实验室 | 20 | 9 | / | 1 | |
| 东南汉族 | 福建汉族a) | FJ | 123 | 30 | 本实验室 | 151 | / | 1 | 1 |
| 岭南汉族 | 广西汉族a) | GX | 124 | 30 | 本实验室 | 99 | 42 | 13 | |
| 广东汉族b) | GD | / | 30 | 本实验室 | 30 | / | / | / | |
附表2
XGBoost算法的超参数调参范围及最优参数"
| 分类器 | 参数 | 参数范围 | 最优参数 |
|---|---|---|---|
| XGBoost | learning_rate | range(0.1,1) | 0.1406 |
| gamma | range(0.01,1) | 0.8593 | |
| lambda | range(1,10) | 5.4916 | |
| max_depth | range(1,10) | 10 | |
| min_child_weight | range(1,5) | 1 | |
| num_boost_round | range(10,500) | 170 | |
| early_stopping_rounds | range(10,100) | 18 |
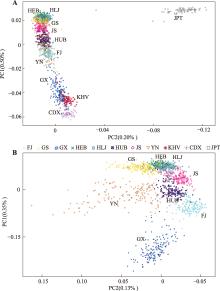
图1
东亚及中国汉族人群的主成分分析结果 A:基于205,041个SNP的东亚人群主成分分析结果;B:基于208,193个SNP的中国汉族人群主成分分析结果。HEB:河北汉族;HLJ:黑龙江汉族;GS:甘肃汉族;JS:江苏汉族;HUB:湖北汉族;FJ:福建汉族;YN:云南汉族;GX:广西汉族;KHV:越南人群;CDX:中国西双版纳傣族人群;JPT:日本人群。"

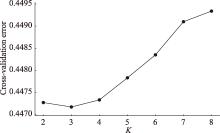
附图1
东亚人群遗传祖先成分分析中不同K值对应的交叉验证误差"
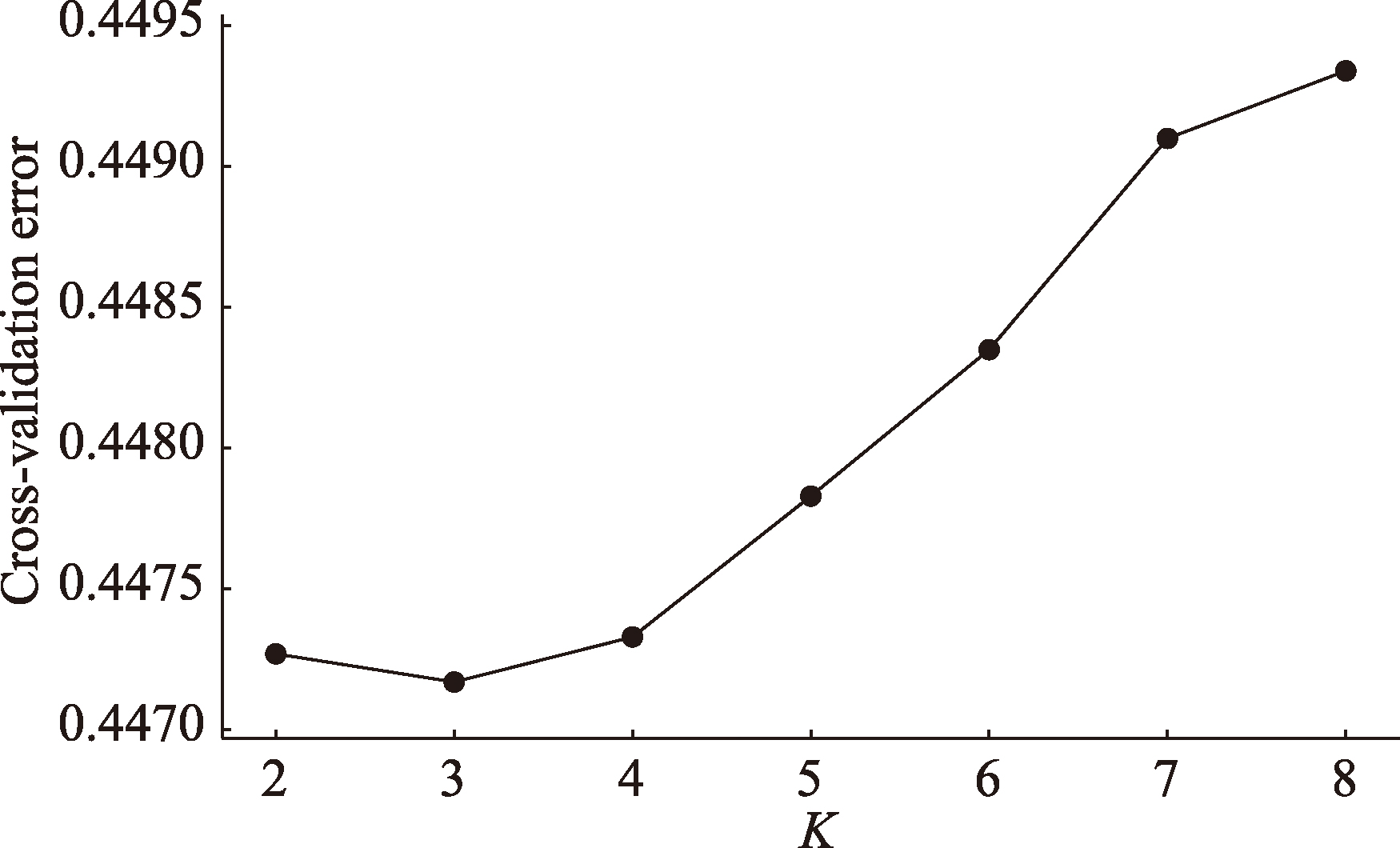
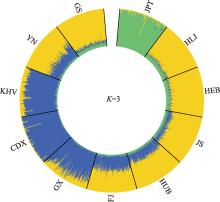
图2
基于205,041个SNP的东亚人群ADMIXTURE分析结果 HEB:河北汉族;HLJ:黑龙江汉族;GS:甘肃汉族;JS:江苏汉族;HUB:湖北汉族;FJ:福建汉族;YN:云南汉族;GX:广西汉族;KHV:越南人群;CDX:中国西双版纳傣族人群;JPT:日本人群。"
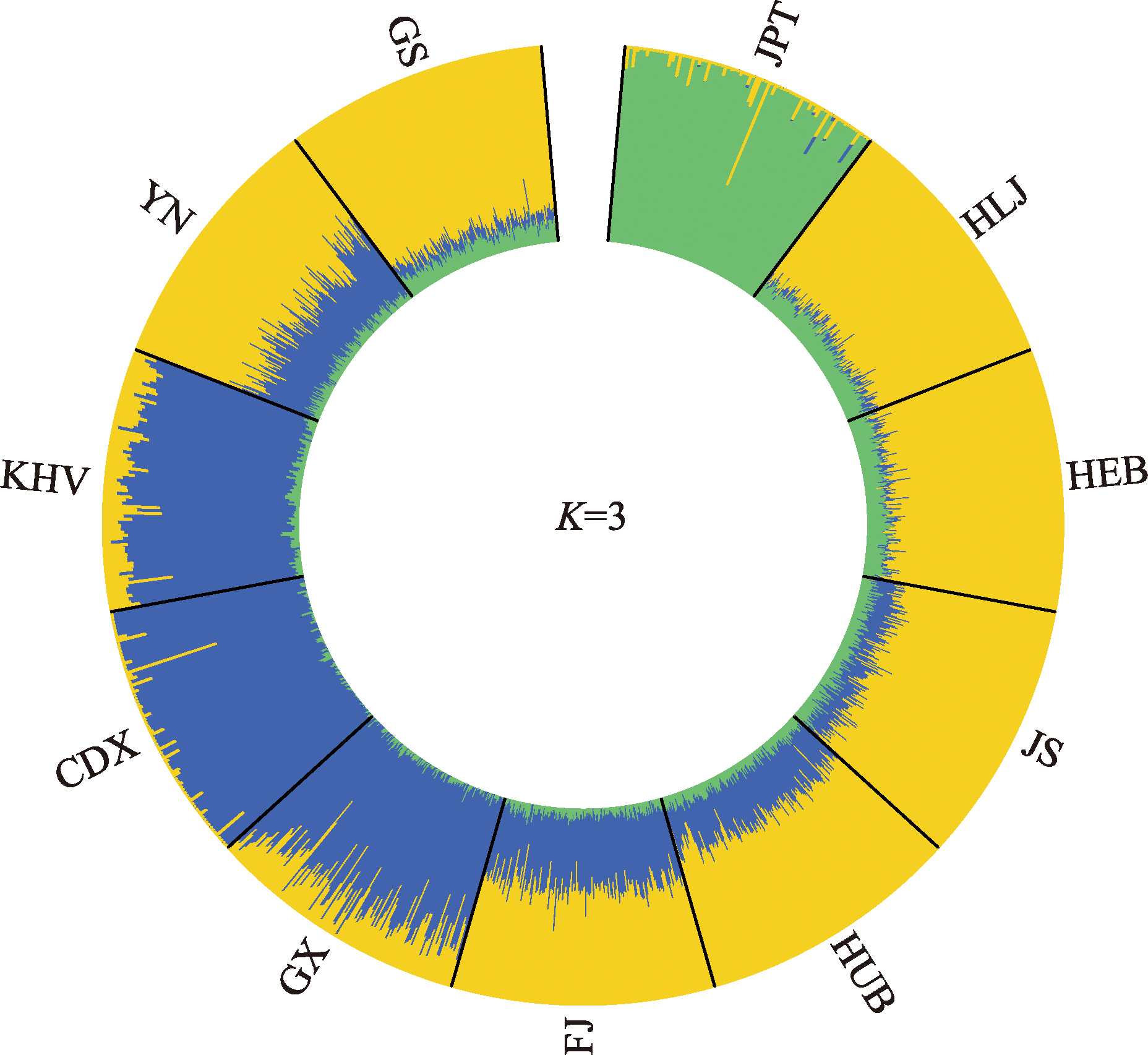

图3
中国不同省份汉族人群的遗传关系 A:不同省份汉族人群间的成对Fst值;B:基于Fst值构建的系统发育树图。HEB:河北汉族;HLJ:黑龙江汉族;GS:甘肃汉族;JS:江苏汉族;HUB:湖北汉族;FJ:福建汉族;YN:云南汉族;GX:广西汉族。"
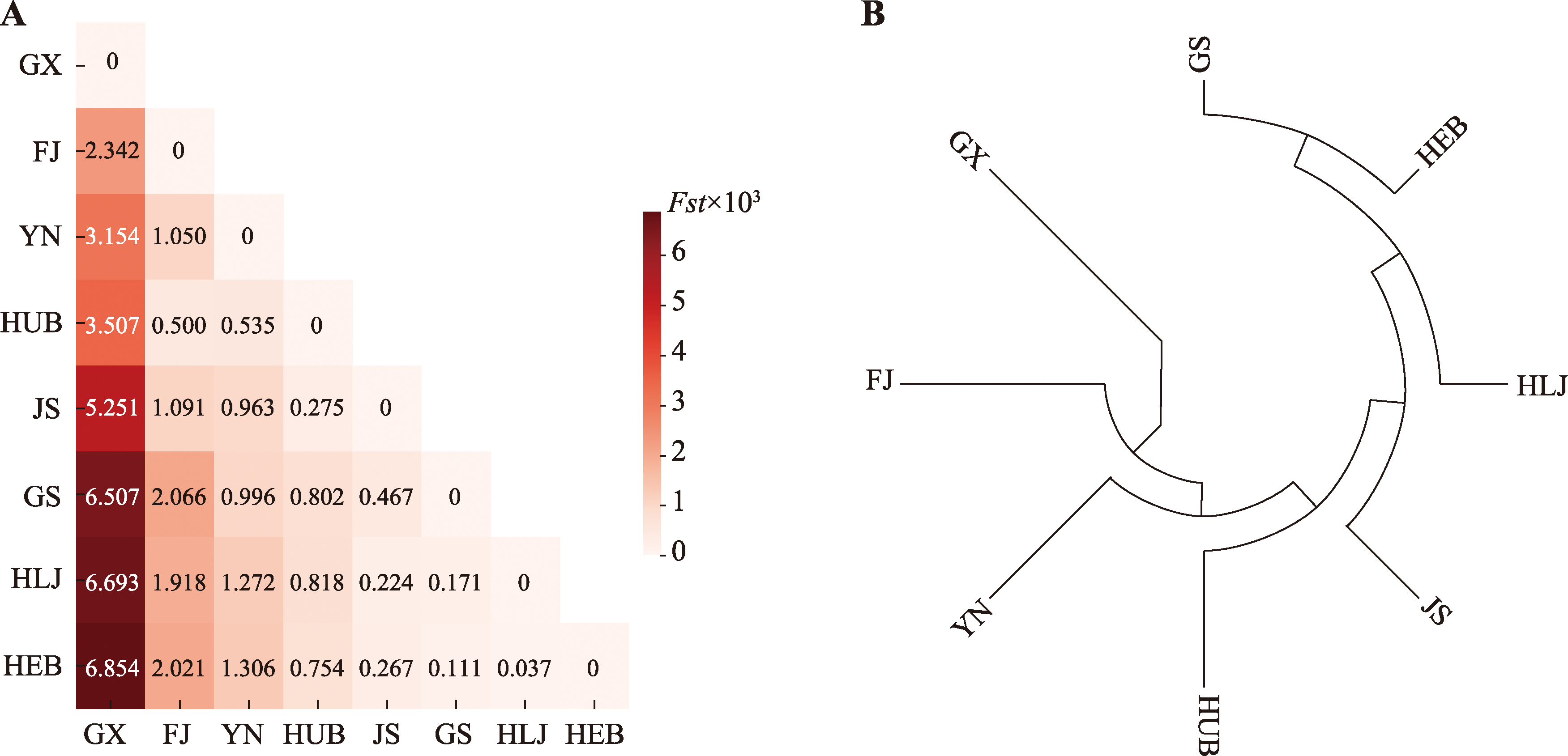
表2
XGBoost、随机森林、K近邻算法准确率的对比分析"
| 方法 | 1stAcc | AccLR | ErrLR | ConsLR | InccLR |
|---|---|---|---|---|---|
| XGBoost | 87.06% | 96.66% | 3.34% | 59.96% | 36.70% |
| 随机森林 | 85.54% | 95.55% | 4.45% | 58.44% | 37.11% |
| K近邻 | 71.08% | 94.03% | 5.97% | 16.78% | 77.25% |
表3
PCA-XGBoost模型在参考集中的预测结果"
| 真实/预测 | 北方汉族 | 西北汉族 | 中部汉族 | 东部汉族 | 东南汉族 | 西南汉族 | 岭南汉族 | 总计 | 1stAcc | AccLR | ConsLR |
|---|---|---|---|---|---|---|---|---|---|---|---|
| 北方汉族 | 215(73) | 16(13) | 2(2) | 13(13) | 246 | 87.40% | 98.78% | 57.72% | |||
| 西北汉族 | 18(10) | 103(59) | 1(1) | 2(2) | 124 | 83.06% | 93.55% | 35.48% | |||
| 中部汉族 | 2(1) | 106(51) | 9(7) | 5(3) | 3(2) | 125 | 84.80% | 95.20% | 44.00% | ||
| 东部汉族 | 19(13) | 1(0) | 10(9) | 93(42) | 123 | 75.61% | 93.50% | 41.46% | |||
| 东南汉族 | 8(5) | 2(1) | 109(16) | 3(3) | 1(1) | 123 | 88.62% | 96.75% | 75.61% | ||
| 西南汉族 | 7(4) | 2(2) | 114(17) | 1(1) | 124 | 91.94% | 97.58% | 78.23% | |||
| 岭南汉族 | 1(1) | 2(1) | 121(10) | 124 | 97.58% | 99.19% | 89.52% | ||||
| 总计 | 989 | 87.06% | 96.66% | 59.96% |
附表3
PCA-KNN模型在参考集中的预测结果"
| 真实/预测 | 北方汉族 | 西北汉族 | 中部汉族 | 东部汉族 | 东南汉族 | 西南汉族 | 岭南汉族 | 总计 | 1stAcc | AccLR | ConsLR |
|---|---|---|---|---|---|---|---|---|---|---|---|
| 北方汉族 | 220(203) | 9(8) | 1(1) | 15(12) | 1(1) | 246 | 89.43% | 98.37% | 6.91% | ||
| 西北汉族 | 69(53) | 50(48) | 5(4) | 124 | 40.32% | 86.29% | 1.61% | ||||
| 中部汉族 | 23(20) | 2(1) | 59(59) | 29(25) | 6(5) | 6(5) | 125 | 42.70% | 92.00% | 0.00% | |
| 东部汉族 | 32(22) | 21(19) | 66(65) | 3(3) | 1(1) | 123 | 53.66% | 90.24% | 0.81% | ||
| 东南汉族 | 1(0) | 17(14) | 7(6) | 98(56) | 123 | 79.67% | 95.93% | 34.15% | |||
| 西南汉族 | 5(4) | 7(6) | 16(10) | 4(1) | 1(1) | 90(60) | 1(1) | 124 | 72.58% | 91.13% | 24.19% |
| 岭南汉族 | 1(1) | 1(1) | 1(1) | 1(1) | 120(46) | 124 | 96.77% | 100.00% | 59.58% | ||
| 总计 | 989 | 71.08% | 94.03% | 16.78% |
附表4
PCA-RF模型在参考集中的预测结果"
| 真实/预测 | 北方汉族 | 西北汉族 | 中部汉族 | 东部汉族 | 东南汉族 | 西南汉族 | 岭南汉族 | 总计 | 1stAcc | AccLR | ConsLR |
|---|---|---|---|---|---|---|---|---|---|---|---|
| 北方汉族 | 213(56) | 13(7) | 20(18) | 246 | 86.59% | 96.75% | 63.82% | ||||
| 西北汉族 | 24(11) | 100(25) | 124 | 80.65% | 89.52% | 60.48% | |||||
| 中部汉族 | 1(0) | 1(0) | 101(81) | 11(11) | 4(2) | 7(6) | 125 | 80.80% | 96.00% | 16.00% | |
| 东部汉族 | 19(11) | 1(1) | 9(8) | 98(78) | 123 | 76.42% | 92.68% | 13.01% | |||
| 东南汉族 | 16(15) | 1(0) | 102(6) | 2(2) | 2(1) | 123 | 82.93% | 97.56% | 78.05% | ||
| 西南汉族 | 1(1) | 5(2) | 4(3) | 114(15) | 124 | 91.94% | 96.77% | 79.84% | |||
| 岭南汉族 | 1(0) | 1(0) | 122(7) | 124 | 98.39% | 98.39% | 92.74% | ||||
| 总计 | 989 | 85.54% | 95.55% | 58.44% |
图4
基于不同主成分(PC)数量的模型准确率"
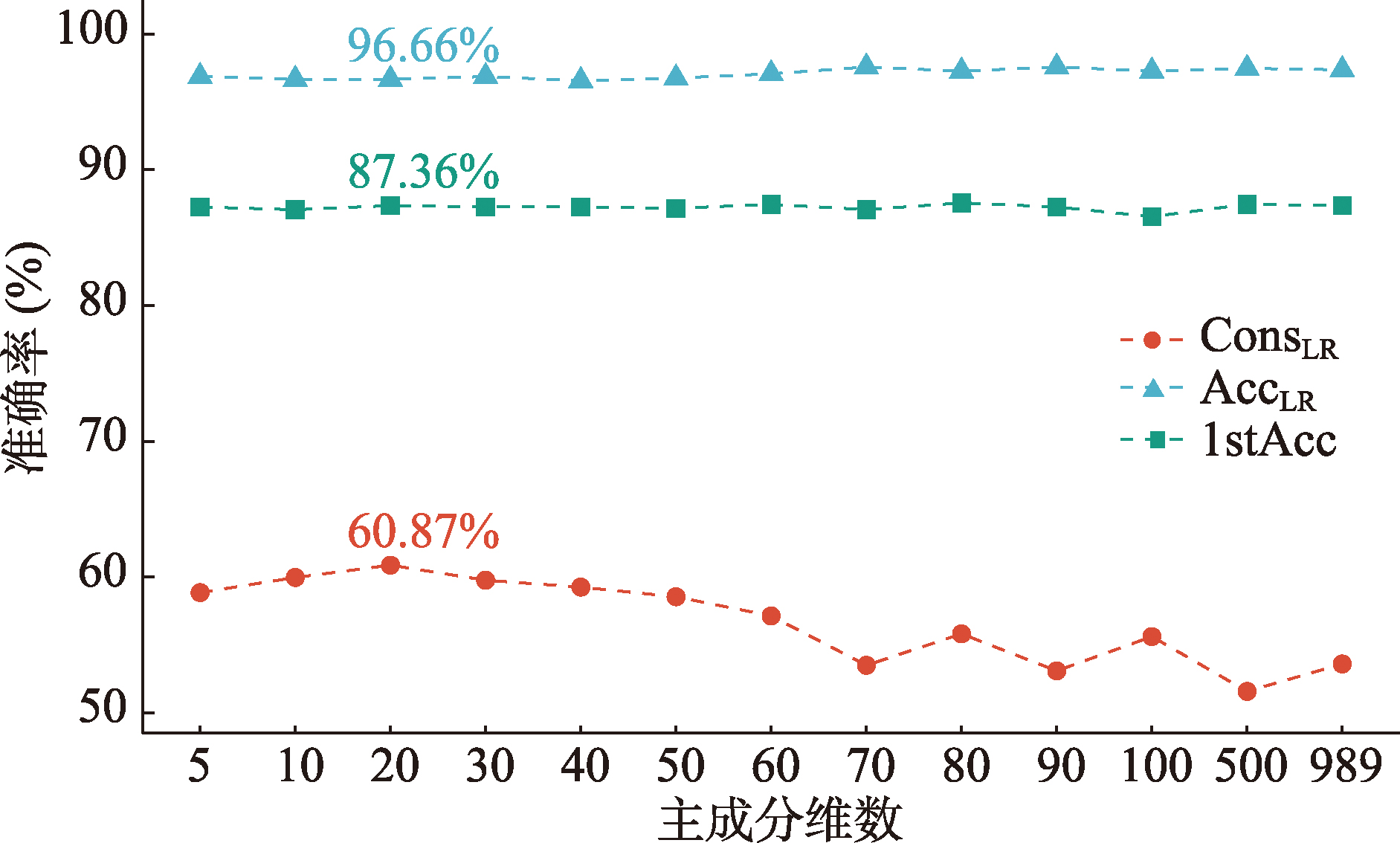
表4
优化后的PCA-XGBoost模型在参考集中的预测结果"
| 真实/预测 | 北方汉族 | 西北汉族 | 中部汉族 | 东部汉族 | 东南汉族 | 西南汉族 | 岭南汉族 | 总计 | 1stAcc | AccLR | ConsLR |
|---|---|---|---|---|---|---|---|---|---|---|---|
| 北方汉族 | 212(73) | 18(16) | 1(1) | 15(12) | 246 | 86.18% | 97.97% | 59.50% | |||
| 西北汉族 | 16(11) | 106(53) | 1(1) | 1(0) | 124 | 85.48% | 95.16% | 42.74% | |||
| 中部汉族 | 2(1) | 103(40) | 10(8) | 6(4) | 4(4) | 125 | 82.40% | 96.00% | 50.40% | ||
| 东部汉族 | 18(12) | 6(6) | 99(46) | 123 | 80.49% | 95.12% | 43.09% | ||||
| 东南汉族 | 7(3) | 3(2) | 110(14) | 2(2) | 1(1) | 123 | 89.43% | 95.93% | 78.04% | ||
| 西南汉族 | 6(4) | 3(2) | 115(21) | 124 | 92.74% | 97.58% | 78.81% | ||||
| 岭南汉族 | 2(1) | 122(3) | 124 | 98.39% | 99.19% | 95.97% | |||||
| 总计 | 989 | 87.66% | 96.87% | 62.39% |
表5
PCA-XGBoost模型在A类测试集的预测结果"
| 真实/预测 | 北方汉族 | 西北汉族 | 中部汉族 | 东部汉族 | 东南汉族 | 西南汉族 | 岭南汉族 | 总计 | 1stAcc | AccLR | ConsLR |
|---|---|---|---|---|---|---|---|---|---|---|---|
| 北方汉族 | 49(17) | 7(7) | 4(4) | 60 | 81.67% | 100.00% | 53.33% | ||||
| 西北汉族 | 4(2) | 25(12) | 1(0) | 30 | 83.33% | 93.33% | 43.33% | ||||
| 中部汉族 | 1(0) | 23(11) | 3(2) | 3(3) | 30 | 76.67% | 93.33% | 40.00% | |||
| 东部汉族 | 4(0) | 26(12) | 30 | 86.67% | 86.67% | 46.67% | |||||
| 东南汉族 | 2(0) | 27(5) | 1(1) | 30 | 90.00% | 93.33% | 73.33% | ||||
| 西南汉族 | 2(1) | 28(4) | 30 | 93.33% | 96.67% | 80.00% | |||||
| 岭南汉族 | 1(1) | 29(1) | 30 | 96.67% | 100.00% | 93.33% | |||||
| 总计 | 240 | 86.25% | 95.42% | 60.41% |

图5
PCA-XGBoost模型在不同测试集上的分类性能评估 A:基于A类测试集的ROC曲线;B:基于B类测试集的ROC曲线。"
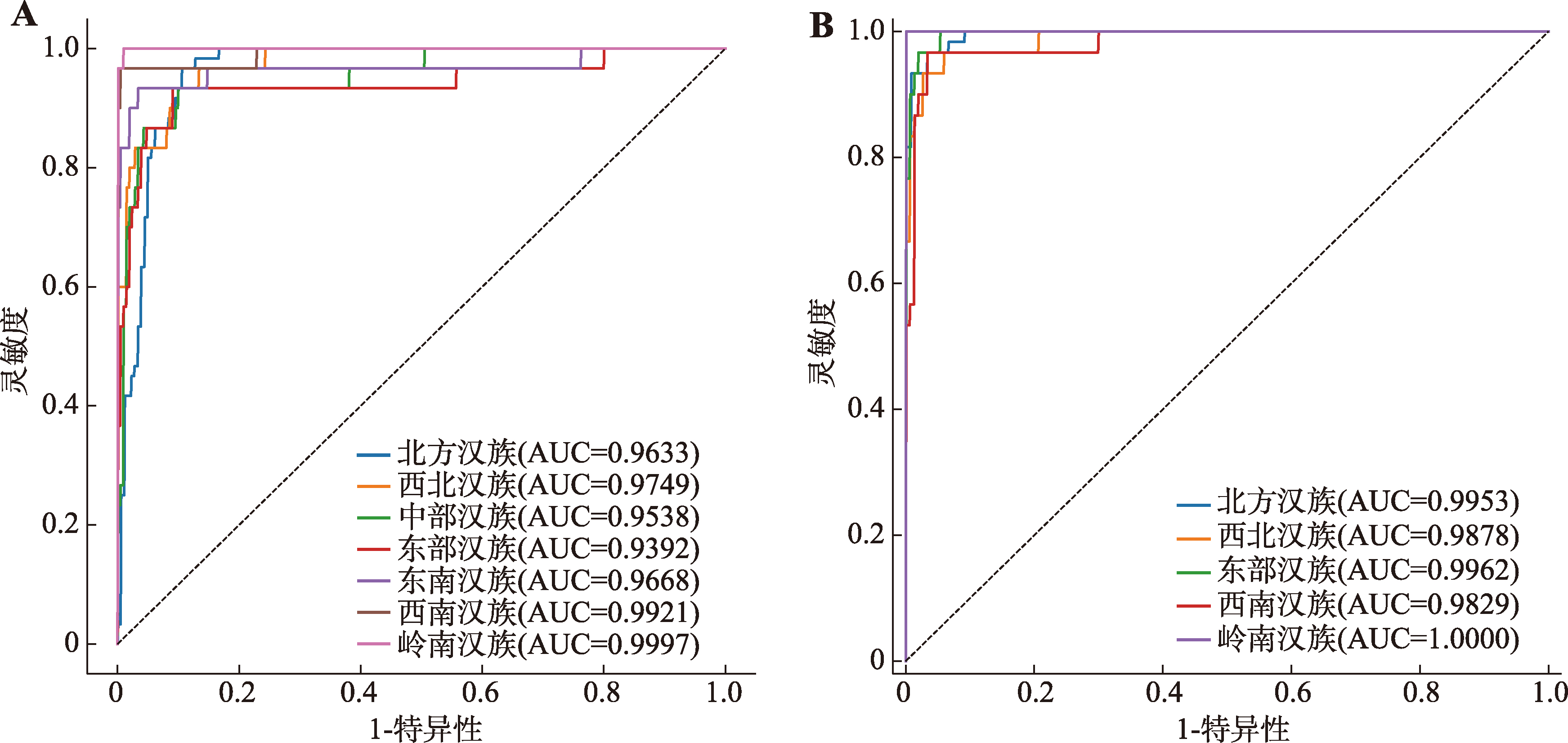
表6
PCA-XGBoost模型在B类测试集的预测结果"
| 真实/预测 | 北方汉族 | 西北汉族 | 中部汉族 | 东部汉族 | 东南汉族 | 西南汉族 | 岭南汉族 | 总计 | 1stAcc | AccLR | ConsLR |
|---|---|---|---|---|---|---|---|---|---|---|---|
| 北方汉族 | 53(23) | 5(5) | 1(1) | 1(1) | 60 | 88.33% | 100.00% | 50.00% | |||
| 西北汉族 | 1(1) | 28(8) | 1(1) | 30 | 93.33% | 100.00% | 66.67% | ||||
| 东部汉族 | 5(5) | 25(9) | 30 | 83.33% | 100.00% | 53.33% | |||||
| 西南汉族 | 10(7) | 3(3) | 17(6) | 30 | 56.67% | 90.00% | 36.67% | ||||
| 岭南汉族 | 30(1) | 30 | 100.00% | 100.00% | 96.67% | ||||||
| 总计 | 180 | 85.00% | 98.33% | 58.89% |
| [1] |
Alladio E, Poggiali B, Cosenza G, Pilli E, Palamenghi A, Marino A, Staiti N. Multivariate statistical approach and machine learning for the evaluation of biogeographical ancestry inference in the forensic field. Sci Rep, 2022, 12(1): 8974.
pmid: 35643723 |
| [2] |
Salvo NM, Olsen GH, Berg T, Janssen K. Biogeographical ancestry analyses using the ForenSeqTM DNA signature prep kit and multiple prediction tools. Genes, 2024, 15(4): 510.
pmid: 38674444 |
| [3] |
Kidd KK, Speed WC, Pakstis AJ, Furtado MR, Fang RX, Madbouly A, Maiers M, Middha M, Friedlaender FR, Kidd JR. Progress toward an efficient panel of SNPs for ancestry inference. Forensic Sci Int Genet, 2014, 10: 23-32.
pmid: 24508742 |
| [4] |
Wei YL, Wei L, Zhao L, Sun QF, Jiang L, Zhang T, Liu HB, Chen JG, Ye J, Hu L, Li CX. A single-tube 27-plex SNP assay for estimating individual ancestry and admixture from three continents. Int J Legal Med, 2016, 130(1): 27-37.
pmid: 25833170 |
| [5] |
Pakstis AJ, Kang LL, Liu LJ, Zhang ZY, Jin TB, Grigorenko EL, Wendt FR, Budowle B, Hadi S, Al Qahtani MS, Morling N, Mogensen HS, Themudo GE, Soundararajan U, Rajeevan H, Kidd JR, Kidd KK. Increasing the reference populations for the 55 AISNP panel: the need and benefits. Int J Legal Med, 2017, 131(4): 913-917.
pmid: 28070634 |
| [6] |
Zhou YS, Jin XY, Wu BL, Zhu BF. Development and performance evaluation of a novel ancestry informative DIP panel for continental origin inference. Front Genet, 2022, 12: 801275.
pmid: 35251118 |
| [7] |
Li CX, Pakstis AJ, Jiang L, Wei YL, Sun QF, Wu H, Bulbul O, Wang P, Kang LL, Kidd JR, Kidd KK. A panel of 74 AISNPs: improved ancestry inference within eastern Asia. Forensic Sci Int Genet, 2016, 23: 101-110.
pmid: 27077960 |
| [8] |
Paschou P, Ziv E, Burchard EG, Choudhry S, Rodriguez- Cintron W, Mahoney MW, Drineas P. PCA-correlated SNPs for structure identification in worldwide human populations. PLoS Genet, 2007, 3(9): e160.
pmid: 17892327 |
| [9] |
Pritchard JK, Stephens M, Donnelly P. Inference of population structure using multilocus genotype data. Genetics, 2000, 155(2): 945-959.
pmid: 10835412 |
| [10] |
Bianco SD, Parca L, Petrizzelli F, Biagini T, Giovannetti A, Liorni N, Napoli A, Carella M, Procaccio V, Lott MT, Zhang SP, Vescovi AL, Wallace DC, Caputo V, Mazza T. APOGEE 2: multi-layer machine-learning model for the interpretable prediction of mitochondrial missense variants. Nat Commun, 2023, 14(1): 5058.
pmid: 37598215 |
| [11] |
Yang QX, Luo L, Lin ZP, Wen W, Zeng WB, Deng H. A machine learning-based predictive model of causality in orthopaedic medical malpractice cases in China. PLoS One, 2024, 19(4): e0300662.
pmid: 38630758 |
| [12] |
Yesilyaprak A, Kumar AK, Agrawal A, Furqan MM, Verma BR, Syed AB, Majid M, Akyuz K, Rayes DL, Chen D, Wang TKM, Cremer PC, Klein AL. Predicting long-term clinical outcomes of patients with recurrent pericarditis. J Am Coll Cardiol, 2024, 84(13): 1193-1204.
pmid: 39217549 |
| [13] |
Cai MM, Lei FZ, Chen M, Lan Q, Wu XL, Mao C, Shi MS, Zhu BF. Systematic analyses of AISNPs screening and classification algorithms based on genome-wide data for forensic biogeographic ancestry inference. Forensic Sci Int, 2024, 357: 111975.
pmid: 38547686 |
| [14] |
Wang CN, Wang SQ, Zhao YR, Liu J, Zhang DQ, Wang FY, Fan H, Li CX, Jiang L. A biogeographical ancestry inference pipeline using PCA-XGBoost model and its application in Asian populations. Forensic Sci Int Genet, 2025, 77: 103239.
pmid: 40037006 |
| [15] | Yang QX, Chen J, Nie SJ, Liu C, Deng H, He GL. Fine-scale biogeographical ancestry inference in Southeast and East Asians via high-efficiency markers and machine learning approaches. Front Ecol Evol, 2025, 13: 1572596. |
| [16] |
Wang MG, Yuan DD, Zou X, Wang Z, Yeh HY, Liu J, Wei LH, Wang CC, Zhu BF, Liu C, He GL. Fine-scale genetic structure and natural selection signatures of southwestern Hans inferred from patterns of genome-wide allele, haplotype, and haplogroup lineages. Front Genet, 2021, 12: 727821.
pmid: 34504517 |
| [17] |
He GL, Wang Z, Guo JX, Wang MG, Zou X, Tang RK, Liu J, Zhang H, Li YX, Hu R, Wei LH, Chen G, Wang CC, Hou YP. Inferring the population history of Tai-Kadai- speaking people and southernmost Han Chinese on Hainan Island by genome-wide array genotyping. Eur J Hum Genet, 2020, 28(8): 1111-1123.
pmid: 32123326 |
| [18] |
Yao HB, Wang MG, Zou X, Li YX, Yang XM, Li AL, Yeh HY, Wang PX, Wang Z, Bai JY, Guo JX, Chen JW, Ding X, Zhang Y, Lin BQ, Wang CC, He GL. New insights into the fine-scale history of western-eastern admixture of the northwestern Chinese population in the Hexi Corridor via genome-wide genetic legacy. Mol Genet Genomics, 2021, 296(3): 631-651.
pmid: 33650010 |
| [19] |
Cong PK, Bai WY, Li JC, Yang MY, Khederzadeh S, Gai SR, Li N, Liu YH, Yu SH, Zhao WW, Liu JQ, Sun Y, Zhu XW, Zhao PP, Xia JW, Guan PL, Qian Y, Tao JG, Xu L, Tian G, Wang PY, Xie SY, Qiu MC, Liu KQ, Tang BS, Zheng HF. Genomic analyses of 10,376 individuals in the Westlake BioBank for Chinese (WBBC) pilot project. Nat Commun, 2022, 13(1): 2939.
pmid: 35618720 |
| [20] |
Cao YN, Li L, Xu M, Feng ZM, Sun XH, Lu JL, Xu Y, Du PN, Wang TG, Hu RY, Ye Z, Shi LX, Tang XL, Yan L, Gao ZN, Chen G, Zhang YF, Chen LL, Ning G, Bi YF, Wang WQ, The ChinaMAP Consortium. The ChinaMAP analytics of deep whole genome sequences in 10,588 individuals. Cell Res, 2020, 30(9): 717-731.
pmid: 32355288 |
| [21] | Gu JQ, Jiang L, Xu JY, Wang H, Wei YL, Li CX. Genetic structure of East Asians based on high-density SNP data. Prog Biochem Biophys, 2023, 50(11): 2739-2752. |
| 顾佳琪, 江丽, 徐景怡, 王寒, 魏以梁, 李彩霞. 基于高密度SNP数据的东亚人群遗传结构研究. 生物化学与生物物理进展, 2023, 50(11): 2739-2752. | |
| [22] |
Li CP, Tian DM, Tang BX, Liu XN, Teng XF, Zhao WM, Zhang Z, Song SH. Genome Variation Map: a worldwide collection of genome variations across multiple species. Nucleic Acids Res, 2021, 49(D1): D1186-D1191.
pmid: 33170268 |
| [23] |
Purcell S, Neale B, Todd-Brown K, Thomas L, Ferreira MAR, Bender D, Maller J, Sklar P, de Bakker PIW, Daly MJ, Sham PC. PLINK: a tool set for whole-genome association and population-based linkage analyses. Am J Hum Genet, 2007, 81(3): 559-575.
pmid: 17701901 |
| [24] |
1000 Genomes Project Consortium, Auton A, Brooks LD, Durbin RM, Garrison EP, Kang HM, Korbel JO, Marchini JL, McCarthy S, McVean GA, Abecasis GR. A global reference for human genetic variation. Nature, 2015, 526(7571): 68-74.
pmid: 26432245 |
| [25] |
Yang J, Lee SH, Goddard ME, Visscher PM. GCTA: a tool for genome-wide complex trait analysis. Am J Hum Genet, 2011, 88(1): 76-82.
pmid: 21167468 |
| [26] |
Alexander DH, Novembre J, Lange K. Fast model-based estimation of ancestry in unrelated individuals. Genome Res, 2009, 19(9): 1655-1664.
pmid: 19648217 |
| [27] |
Ito K, Murphy D. Application of ggplot2 to pharmacometric graphics. CPT Pharmacometrics Syst Pharmacol, 2013, 2(10): e79.
pmid: 24132163 |
| [28] |
Danecek P, Auton A, Abecasis G, Albers CA, Banks E, DePristo MA, Handsaker RE, Lunter G, Marth GT, Sherry ST, McVean G, Durbin R, 1000 Genomes Project Analysis Group. The variant call format and VCFtools. Bioinformatics, 2011, 27(15): 2156-2158.
pmid: 21653522 |
| [29] |
Kumar S, Stecher G, Li M, Knyaz C, Tamura K. MEGA X: molecular evolutionary genetics analysis across computing platforms. Mol Biol Evol, 2018, 35(6): 1547-1549.
pmid: 29722887 |
| [30] | Yao HT, Jiang L, Wang CN, Fan H, Li CX. Research on the intercontinental population biogeographic ancestral inference model based on PCA-XGBoost method. Prog Biochem Biophys, 2024, 51(12): 3292-3309. |
| 姚昊天, 江丽, 王春年, 范虹, 李彩霞. 基于PCA- XGBoost方法的洲际人群生物地理祖源推断模型研究. 生物化学与生物物理进展, 2024, 51(12): 3292-3309. | |
| [31] | Chen TQ, Guestrin C. XGBoost: a scalable tree boosting system. In: Proceedings of the 22nd ACM SIGKDD International Conference on Knowledge Discovery and Data Mining (KDD'16). Association for Computing Machinery, New York, NY, USA, 2016, 785-794. |
| [32] |
Rigatti SJ. Random forest. J Insur Med, 2017, 47(1): 31-39.
pmid: 28836909 |
| [33] | Hastie T, Tibshirani R. Discriminant adaptive nearest neighbor classification and regression. In: Proceedings of the 9th International Conference on Neural Information Processing Systems (NIPS'95). MIT Press, Cambridge, MA, USA, 1995, 409-415. |
| [34] | He GL, Li YX, Zou X, Yeh HY, Tang RK, Wang PX, Bai JY, Yang XM, Wang Z, Guo JX, Chen JW, Chen J, Yang MQ, Zhao J, Sun J, Zhu KY, Ma H, Wang R, Yang WJ, Hu R, Wei LH, Hou YP, Wang MG, Chen G, Wang CC. Northern gene flow into southeastern East Asians inferred from genome-wide array genotyping. J Syst Evol, 2023, 61(1): 179-197. |
| [35] |
Wen B, Li H, Lu DR, Song XF, Zhang F, He YG, Li F, Gao Y, Mao XY, Zhang L, Qian J, Tan JZ, Jin JZ, Huang W, Deka RJ, Su B, Chakraborty R, Jin L. Genetic evidence supports demic diffusion of Han culture. Nature, 2004, 431(7006): 302-305.
pmid: 15372031 |
| [36] |
Zhang P, Luo HX, Li YY, Wang Y, Wang JJ, Zheng Y, Niu YW, Shi YR, Zhou HH, Song TR, Kang Q, Han100K Initiative, Xu T, He SM. NyuWa Genome resource: a deep whole-genome sequencing-based variation profile and reference panel for the Chinese population. Cell Rep, 2021, 37(7): 110017.
pmid: 34788621 |
| [37] |
Chen PY, Wu J, Luo L, Gao HY, Wang MG, Zou X, Li YX, Chen G, Luo HB, Yu LM, Han YY, Jia FQ, He GL. Population genetic analysis of modern and ancient DNA variations yields new insights into the formation, genetic structure, and phylogenetic relationship of Northern Han Chinese. Front Genet, 2019, 10: 1045.
pmid: 31737039 |
| [38] |
Liu SY, Huang SJ, Chen F, Zhao LJ, Yuan YY, Francis SS, Fang L, Li ZL, Lin L, Liu R, Zhang Y, Xu HX, Li SK, Zhou YW, Davies RW, Liu Q, Walters RG, Lin K, Ju J, Korneliussen T, Yang MA, Fu QM, Wang J, Zhou LJ, Krogh A, Zhang HY, Wang W, Chen ZM, Cai ZM, Yin Y, Yang HM, Mao M, Shendure J, Wang J, Albrechtsen A, Jin X, Nielsen R, Xu X. Genomic analyses from non-invasive prenatal testing reveal genetic associations, patterns of viral infections, and Chinese population history. Cell, 2018, 175(2): 347-359.e14.
pmid: 30290141 |
| [39] | Zhou JB, Zhang XP, Li X, Sui J, Zhang S, Zhong H, Zhang QX, Zhang XM, Huang H, Wen YF. Genetic structure and demographic history of Northern Han people in Liaoning Province inferred from genome-wide array data. Front Ecol Evol, 2022, 10: 1014024. |
| [40] |
Chiang CWK, Mangul S, Robles C, Sankararaman S. A comprehensive map of genetic variation in the world’s largest ethnic group—Han Chinese. Mol Biol Evol, 2018, 35(11): 2736-2750.
pmid: 30169787 |
| [41] |
Chen JM, Zheng HF, Bei JX, Sun LD, Jia WH, Li T, Zhang FR, Seielstad M, Zeng YX, Zhang XJ, Liu JJ. Genetic structure of the Han Chinese population revealed by genome-wide SNP variation. Am J Hum Genet, 2009, 85(6): 775-785.
pmid: 19944401 |
| [42] |
Li W, Yin YB, Quan XW, Zhang H. Gene expression value prediction based on XGBoost algorithm. Front Genet, 2019, 10: 1077.
pmid: 31781160 |
| [43] |
Deng XS, Li M, Deng SB, Wang L. Hybrid gene selection approach using XGBoost and multi-objective genetic algorithm for cancer classification. Med Biol Eng Comput, 2022, 60(3): 663-681.
pmid: 35028863 |
| [44] |
Watson DS. Interpretable machine learning for genomics. Hum Genet, 2022, 141(9): 1499-1513.
pmid: 34669035 |
| [45] |
Musolf AM, Holzinger ER, Malley JD, Bailey-Wilson JE. What makes a good prediction? Feature importance and beginning to open the black box of machine learning in genetics. Hum Genet, 2022, 141(9): 1515-1528.
pmid: 34862561 |
| [46] |
Gaspar HA, Breen G. Probabilistic ancestry maps: a method to assess and visualize population substructures in genetics. BMC Bioinform, 2019, 20(1): 116.
pmid: 30845922 |
| [47] |
Ausmees K, Nettelblad C. A deep learning framework for characterization of genotype data. G3 (Bethesda), 2022, 12(3): jkac020.
pmid: 35078229 |
| [48] | Montserrat DM, Bustamante C, Ioannidis A. Lai-net: local-ancestry inference with neural networks. ICASSP 2020-2020 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP). IEEE, 2020, 1314-1318. |
| [49] |
Karim MR, Cochez M, Zappa A, Sahay R, Rebholz- Schuhmann D, Beyan O, Decker S. Convolutional embedded networks for population scale clustering and bio-ancestry inferencing. IEEE/ACM Trans Comput Biol Bioinform, 2020, 19(1): 369-382.
pmid: 32750845 |
| [50] |
Battey CJ, Ralph PL, Kern AD. Predicting geographic location from genetic variation with deep neural networks. eLife, 2020, 9: e54507.
pmid: 32511092 |
| [51] |
Soumare H, Rezgui S, Gmati N, Benkahla A. New neural network classification method for individuals ancestry prediction from SNPs data. BioData Min, 2021, 14(1): 30.
pmid: 34183066 |
| [52] |
Prugnolle F, Manica A, Balloux F. Geography predicts neutral genetic diversity of human populations. Curr Biol, 2005, 15(5): R159-R160.
pmid: 15753023 |
| [53] |
Battey CJ, Ralph PL, Kern AD. Space is the place: effects of continuous spatial structure on analysis of population genetic data. Genetics, 2020, 215(1): 193-214.
pmid: 32209569 |
| [54] |
Li YC, Ye WJ, Jiang CG, Zeng Z, Tian JY, Yang LQ, Liu KJ, Kong QP. River valleys shaped the maternal genetic landscape of Han Chinese. Mol Biol Evol, 2019, 36(8): 1643-1652.
pmid: 31112995 |
| [55] |
Gao Y, Zhang C, Yuan LY, Ling YC, Wang XJ, Liu C, Pan YW, Zhang XX, Ma XX, Wang YC, Lu Y, Yuan K, Ye W, Qian JQ, Chang HD, Cao RF, Yang X, Ma L, Ju YH, Dai L, Tang YY, The Han100K Initiative, Zhang GQ, Xu SH. PGG. Han: the Han Chinese genome database and analysis platform. Nucleic Acids Res, 2020, 48(D1): D971-D976.
pmid: 31584086 |
| [56] |
Li ZC, Jiang XS, Fang MY, Bai Y, Liu SY, Huang SJ, Jin X. CMDB: the comprehensive population genome variation database of China. Nucleic Acids Res, 2023, 51(D1): D890-D895.
pmid: 35871305 |
| [57] |
Wang CC, Li H. Inferring human history in East Asia from Y chromosomes. Investig Genet, 2013, 4(1): 11.
pmid: 23731529 |
| [58] |
Moutsouri I, Manoli P, Christofi V, Bashiardes E, Keravnou A, Xenophontos S, Cariolou MA. Deciphering the maternal ancestral lineage of Greek Cypriots, Armenian Cypriots and Maronite Cypriots. PLoS One, 2024, 19(2): e0292790.
pmid: 38315645 |
| [59] | Yu HX, Zhang XP, Wei LH. The 30-100 patrilineal nomenclature system for eastern Eurasian populations. Hereditas(Beijing), 2025, 47(6): 660-671. |
| 于会新, 张咸鹏, 韦兰海. 欧亚大陆东部人群父系30-100分类体系. 遗传, 2025, 47(6): 660-671. | |
| [60] |
Yang T, Liu YH, Zou S, Li XP, Wang ZY, Luo LT, Tang RK, Liu C, Hu LP, He GL, Nie SJ, Wang MG. Patrilineages of ethnolinguistically diverse populations reveal multifactorial influences on Chinese paternal population stratification. BMC Biol, 2025, 23(1): 341.
pmid: 41250068 |
| [61] |
Lee J, Yang S, Baik JY, Liu XX, Tan Z, Li DW, Wen ZX, Hou BJ, Duong-Tran D, Chen TL, Shen L. Knowledge- driven feature selection and engineering for genotype data with large language models. AMIA Jt Summits Transl Sci Proc, 2025, 2025: 250-259.
pmid: 40502214 |
| [62] |
Ali S, Qadri YA, Ahmad K, Lin ZZ, Leung MF, Kim SW, Vasilakos AV, Zhou T. Large language models in genomics—a perspective on personalized medicine. Bioengineering (Basel), 2025, 12(5): 440.
pmid: 40428059 |
| [1] | 戴律, 汤子琛, 贾镇, 江丽, 赵传桐, 赵志远, 赵雯婷, 李彩霞. SNP密度对亲缘关系推断效能的影响及IBS算法的机器学习优化[J]. 遗传, 2026, 48(6): 570-588. |
| [2] | 贺航, 张金佩, 张楚楚, 姜成涛, 税薇薇, 郝世诚, 来宜雯, 缪磊, 王秋娟, 郭小森, 袁丽. 中国北方汉族人群81个常染色体STR基因座多态性研究及突变调查[J]. 遗传, 2026, 48(5): 483-505. |
| [3] | 李志宏, 陈淼琪, 袁晓珺, 黄华君, 黄琬婷, 周飘雁, 曾晨, 冯许诺, 杨洛瑶, 黄树强, 谭翠钰, 陈彩蓉, 颜秋霞. 基于microRNA与生物信息学筛选非梗阻性无精子症的生物标志物[J]. 遗传, 2026, 48(3): 301-312. |
| [4] | 梁卉, 王雪, 司敬方, 张毅. 利用基因组标记和机器学习算法对中国牛品种的分类准确性研究[J]. 遗传, 2024, 46(7): 530-539. |
| [5] | 郑慧怡, 吴华煊, 杜志强. 肠道宏基因组图像增强和深度学习改善代谢性疾病分类预测精度[J]. 遗传, 2024, 46(10): 886-896. |
| [6] | 章子怡, 王棨临, 张俊有, 段迎迎, 刘家欣, 刘赵硕, 李春燕. 多组学数据驱动的机器学习模型在乳腺癌生存及治疗响应预测中的应用[J]. 遗传, 2024, 46(10): 820-832. |
| [7] | 陈栋, 王书杰, 赵真坚, 姬祥, 申琦, 余杨, 崔晟頔, 王俊戈, 陈子旸, 王金勇, 郭宗义, 吴平先, 唐国庆. 基于机器学习的猪生长性状基因组预测[J]. 遗传, 2023, 45(10): 922-932. |
| [8] | 王雪倩, 张庆珍, 程鹏, 董婷婷, 李卫国, 周喆, 王升启. 中国汉族人群66个InDel基因座的遗传多态性[J]. 遗传, 2022, 44(4): 335-345. |
| [9] | 孔永强, 刘金凯, 顾佳琪, 徐景怡, 郑雨诺, 魏以梁, 伍少远. 南-北方汉族人、韩国人和日本人遗传划分机器学习模型优化方案[J]. 遗传, 2022, 44(11): 1028-1043. |
| [10] | 李茜, 王浩宇, 曹悦岩, 朱强, 舒潘寅, 侯婷芸, 王雨婷, 张霁. 微单倍型遗传标记的法医基因组学研究[J]. 遗传, 2021, 43(10): 962-971. |
| [11] | 刘志勇, 任贺, 陈冲, 张京晶, 张晓梦, 石妍, 石林玉, 陈滢, 程凤, 贾莉, 陈曼, 范庆炜, 张家榕, 李万婷, 王萌春, 任子林, 刘雅诚, 倪铭, 孙宏钰, 严江伟. 基于有限突变模型和大规模数据的19个常染色体STR的实际突变率研究[J]. 遗传, 2021, 43(10): 949-961. |
| [12] | 刘明, 李祎, 杨亚芳, 晏于文, 刘凡, 李彩霞, 曾发明, 赵雯婷. 中国汉族人群脸部特征相关SNP位点研究[J]. 遗传, 2020, 42(7): 680-690. |
| [13] | 胡雅丽, 戴睿, 刘永鑫, 张婧赢, 胡斌, 储成才, 袁怀波, 白洋. 水稻典型品种日本晴和IR24根系微生物组的解析[J]. 遗传, 2020, 42(5): 506-518. |
| [14] | 张桂珊, 杨勇, 张灵敏, 戴宪华. 机器学习方法在CRISPR/Cas9系统中的应用[J]. 遗传, 2018, 40(9): 704-723. |
| [15] | 赵学彤, 杨亚东, 渠鸿竹, 方向东. 组学时代下机器学习方法在临床决策支持中的应用[J]. 遗传, 2018, 40(9): 693-703. |
| 阅读次数 | ||||||
|
全文 |
|
|||||
|
摘要 |
|
|||||

www.chinagene.cn
备案号:京ICP备09063187号-4
总访问:,今日访问:,当前在线:
