
遗传 ›› 2020, Vol. 42 ›› Issue (8): 799-809.doi: 10.16288/j.yczz.20-080
陈凤珍1, 游丽金1, 杨帆1, 王丽娜1, 郭学芹1, 高飞1, 华聪1, 谈聪1, 方林2, 单日强3, 曾文君1, 王博1, 王韧1( ), 徐讯1,2,4(), 魏晓锋1()
), 徐讯1,2,4(), 魏晓锋1()
收稿日期:2020-03-23
修回日期:2020-05-23
出版日期:2020-08-20
发布日期:2020-06-01
通讯作者:
王韧,徐讯,魏晓锋
E-mail:wangren@cngb.org;xuxun@genomics.cn;weixiaofeng@cngb.org
作者简介:陈凤珍,本科,研究方向:生物大数据。E-mail: 基金资助:
Fengzhen Chen1, Lijin You1, Fan Yang1, Lina Wang1, Xueqin Guo1, Fei Gao1, Cong Hua1, Cong Tan1, Lin Fang2, Riqiang Shan3, Wenjun Zeng1, Bo Wang1, Ren Wang1(), Xun Xu1,2,4(), Xiaofeng Wei1()
Received:2020-03-23
Revised:2020-05-23
Online:2020-08-20
Published:2020-06-01
Contact:
Wang Ren,Xu Xun,Wei Xiaofeng
E-mail:wangren@cngb.org;xuxun@genomics.cn;weixiaofeng@cngb.org
Supported by:摘要:
国家基因库生命大数据平台(China National GeneBank DataBase, CNGBdb)是一个致力于生命科学多组学数据归档和开放共享的数据库平台,是深圳国家基因库的核心功能“三库两平台”中生物信息数据库的对外服务平台,拥有深圳国家基因库丰富的样本资源、数据资源、合作项目资源和强大的数据计算和分析能力等优势。生命科学研究已经进入到了一个以高通量多组学数据为基础的大数据时代,迫切需要加强国际合作和信息共享。随着中国经济的发展和在生命科学研究领域的研究项目投入力度的加大,需要建立相关的生命大数据归档和共享的平台, 来促进我国生命科学研究项目中生成的基因组学数据的系统管理、开放共享与合理利用。目前,CNGBdb主要提供生命科学研究相关的数据归档、知识搜索、数据管理、数据计算和数据服务等服务。其归档和共享的数据类型,主要包括项目、样本、实验、测序、组装、变异、序列等。截止2020年5月22号, CNGBdb已接受了全球生命科学科研工作者提交的研究项目达2176个,归档的基因组学数据量超过2221 TB。未来,CNGBdb将继续推动生命科学研究多组学数据的开放共享和产业应用,完善基因组学数据的归档和共享功能,提升其服务生命科学数据开放共享的能力。CNGBdb的网址是:https://db.cngb.org/。
陈凤珍, 游丽金, 杨帆, 王丽娜, 郭学芹, 高飞, 华聪, 谈聪, 方林, 单日强, 曾文君, 王博, 王韧, 徐讯, 魏晓锋. CNGBdb:国家基因库生命大数据平台[J]. 遗传, 2020, 42(8): 799-809.
Fengzhen Chen, Lijin You, Fan Yang, Lina Wang, Xueqin Guo, Fei Gao, Cong Hua, Cong Tan, Lin Fang, Riqiang Shan, Wenjun Zeng, Bo Wang, Ren Wang, Xun Xu, Xiaofeng Wei. CNGBdb: China National GeneBank DataBase[J]. Hereditas(Beijing), 2020, 42(8): 799-809.
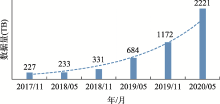
图1
CNSA归档数据量统计图"
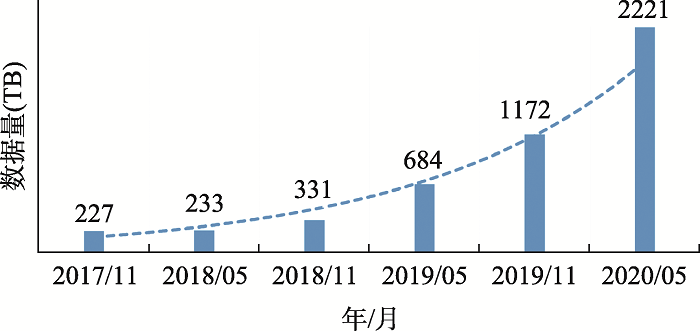
表1
知识搜索服务数据"
| 数据类型 | 索引量(万) | 主要外源数据库 | 主要信息 |
|---|---|---|---|
| 文献 | 2947.19 | GigaScience、PubMed和Europe PMC | 文献标题、摘要、医学关键词、引用和参考文献和文献相关数据等 |
| 基因 | 2274.41 | NCBI Gene | 基因名称、染色体位置、基因产物和它的属性、基因所在的基因组、基因序列和基因变异等 |
| 变异 | 76323.01 | dbSNP[ | 变异名称(HGVS名称)、基因组位置、相关物种、人群频率以及变异数据与疾病、表型和文献等 |
| 蛋白 | 13406.59 | Uniprot[ | 蛋白名称、蛋白长度、物种和编码蛋白的基因等 |
| 序列 | 213665.12 | NCBI Refseq[ | 序列名称、序列长度、物种和fastq序列文件等 |
| 项目 | 35.63 | NCBI BioProject[ | 项目的名称、描述和数据类型等 |
| 样本 | 1007.36 | NCBI BioSample[ | 样本的名称、物种、样本类型和描述等 |
| 实验 | 5515.46 | NCBI SRA[ | 实验的题目、测序平台、文库构建策略、文库来源和文库选项等 |
| 组装 | 0.24 | NCBI Assembly[ | 组装的名称、分子类型、测序技术和组装方法等 |

图2
1KGP文献推荐知识图谱 当前文献(红色圆点)是整个图谱的中心和起点,与其相连的绿、黄、蓝3个节点分别代表这篇文献的作者、相关推荐文献和MeSH(医学主题词)。这4个大的主节点构成了图谱的主干。"
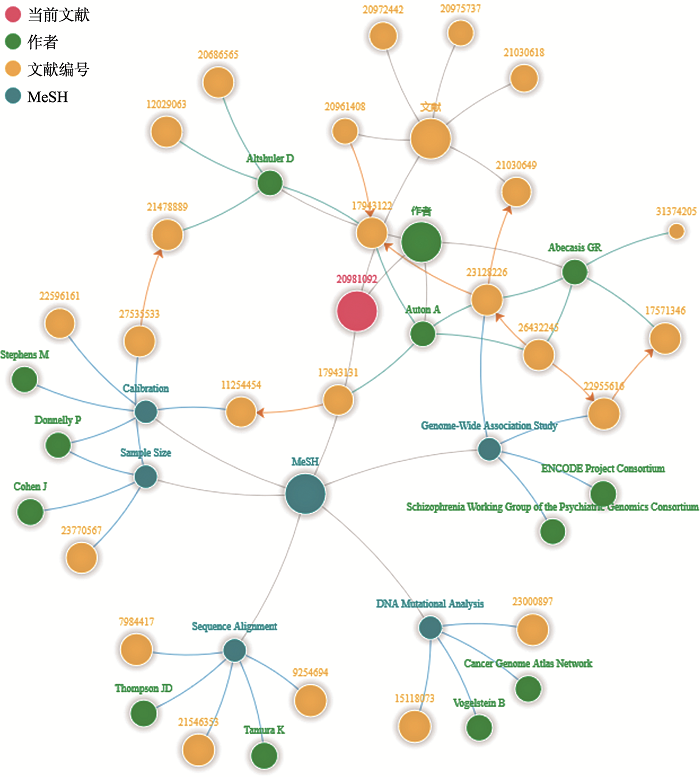
表2
BLAST工具数据资源"
| 数据源 | 数据库名称 | 数据库编号 | 数据库格式版本 |
|---|---|---|---|
| CNGB | The 1000 Plants Project | onekp | v5 |
| Microbiome DataBase | microbiome | v5 | |
| Pan Immune Repertoire Database | pird | v5 | |
| The Transcriptomes of 1,000 Fishes Project | fisht1k | v5 | |
| The Bird 10,000 Genomes Project | b10k | v5 | |
| NCBI | Nucleotide collection | nt | v5 |
| Reference proteins | refseq_protein | v4 | |
| 16S ribosomal RNA sequences | 16smicrobial | v4 | |
| Human genomic | human_genomic | v4 | |
| RefSeq Representative genomes | refseq_representative_genomes | v4 | |
| Non-human organisms genomic | other_genomic | v4 | |
| Human RefSeqGene sequences | refseqgene | v4 | |
| Genomic survey sequences | gss | v4 | |
| Reference genomic sequences | refseq_genomic | v4 | |
| High throughput genomic sequences | htgs | v4 | |
| Transcriptome Shotgun Assembly | tsa | v4 | |
| Expressed sequence tags | est | v4 | |
| Patent sequences | pat | v4 | |
| Sequence tagged sites | sts | v4 | |
| Protein Data Bank | pdb | v4 | |
| Metagenomic sequences | env | v4 |
表3
CNGBdb用户已创建的部分数据集"
| 分类 | 数据集名称 | 简要介绍 | 网址 |
|---|---|---|---|
| 植物 | 10,000 Plant Genomes Project | 万种植物基因组项目数据集 | https://db.cngb.org/datamart/plant/DATApla1/ |
| The 3000 Rice Genomes Project | 3000水稻项目数据集 | https://db.cngb.org/datamart/plant/DATApla2/ | |
| 1000 Plant Transcriptomes | 千种植物转录组项目数据集 | https://db.cngb.org/datamart/plant/DATApla4/ | |
| Data of Ruili Botanical Garden | 瑞丽珍稀植物园689种植物 基因组测序数据 | https://db.cngb.org/datamart/plant/DATApla5/ | |
| 动物 | The B10K Genomes Project | 万种鸟基因组项目数据集 | https://db.cngb.org/datamart/animal/DATAani1/ |
| 1K Insect Transcriptome | 千种昆虫转录组数据集 | https://db.cngb.org/datamart/animal/DATAani3/ | |
| Transcriptomes of 1000 Fishes | 千种鱼转录组数据集 | https://db.cngb.org/datamart/animal/DATAani2/ | |
| Vertebrate Genomes 10K | 万种脊椎动物数据集 | https://db.cngb.org/datamart/animal/DATAani5/ | |
| Life Periodic Plan (LPP) | 生命周期表项目数据集 | https://db.cngb.org/datamart/animal/DATAani6/ | |
| 微生物 | 1520 reference genomes | 覆盖人体肠道中所有主要细菌门和 属的1520个基因组数据集 | https://db.cngb.org/datamart/microbe/DATAmic1/ |
| Earth Microbiome Project | 地球微生物组项目数据集 | https://db.cngb.org/datamart/microbe/DATAmic4/ | |
| 1000 Fungal Genomes Project | 千种真菌基因组项目数据集 | https://db.cngb.org/datamart/microbe/DATAmic7/ | |
| MetaHIT (metagenomics of humanintestinal tract) | 欧盟的肠道微生物组计划数据集 | https://db.cngb.org/datamart/microbe/DATAmic5/ | |
| Human Microbiome Project | 人类微生物组项目数据集 | https://db.cngb.org/datamart/microbe/DATAmic3/ | |
| 人群 | WGS of 175 Mongolians | 175个蒙古人基因组数据集 | https://db.cngb.org/datamart/other/DATAoth1/ |
| 1000 Genomes Project (human) | 千人基因组项目数据集 | https://db.cngb.org/datamart/other/DATAoth2/ |
| [1] | Wang B, Liu F, Zhang EC, Wo CL, Chen J, Qian PY, Lu HR, Zeng WJ, Chen T, Wei JP, Wan Q, Wang R, Xu X . The China National GeneBank─owned by all, completed by all and shared by all. Hereditas(Beijing), 2019,41(8):761-772. |
| 王博, 刘芳, 张二春, 沃晨亮, 陈振家, 钱璞毅, 卢浩荣, 曾文君, 陈泰, 危金普, 万仟, 王韧, 徐讯 . 国家基因库: 共有、共为、共享. 遗传, 2019,41(8):761-772. | |
| [2] |
Clarke L, Fairley S, Zheng-Bradley X, Streeter I, Perry E, Lowy E, Tassé AM, Flicek P . The international Genome sample resource (IGSR): A worldwide collection of genome variation incorporating the 1000 Genomes Project data. Nucleic Acids Res, 2017,45(D1):D854-D859.
doi: 10.1093/nar/gkw829 pmid: 27638885 |
| [3] |
Consortium ICG . International network of cancer genome projects. Nature, 2010,464(7291):993-938.
doi: 10.1038/nature08987 pmid: 20393554 |
| [4] |
Yu J, Hu SN, Wang J, Wong GKS, Li SG, Liu B, Deng YJ, Dai L, Zhou Y, Zhang XQ, Cao ML, Liu J, Sun JD, Tang JB, Chen YJ, Huang XB, Lin W, Ye C, Tong W, Cong LJ, Geng JN, Han YJ, Li L, Li W, Hu GQ, Huang XG, Li WJ, Li J, Liu ZW, Li L, Liu JP, Qi QH, Liu JS, Li L, Li T, Wang XJ, Lu H, Wu TT, Zhu M, Ni PX, Han H, Dong W, Ren XY, Feng XL, Cui P, Li XR, Wang H, Xu X, Zhai WX, Xu Z, Zhang JS, He SJ, Zhang JG, Xu JC, Zhang KL, Zheng XW, Dong JH, Zeng WY, Tao L, Ye J, Tan J, Ren XD, Chen XW, He J, Liu DF, Tian W, Tian CG, Xia HG, Bao QY, Li G, Gao H, Cao T, Wang J, Zhao WM, Li P, Chen W, Wang XD, Zhang Y, Hu JF, Wang J, Liu S, Yang G, Zhang GY, Xiong YQ, Li ZJ, Mao L, Zhou CS, Zhu Z, Chen RS, Hao BL, Zheng WM, Chen SY, Guo W, Li GJ, Liu SQ, Tao M, Wang J, Zhu LH, Yuan LP, Yang HM . A draft sequence of the rice genome (Oryza sativa L. ssp. indica). Science, 2002,296(5565):79-92.
doi: 10.1126/science.1068037 pmid: 11935017 |
| [5] |
International RGSP . The map-based sequence of the rice genome. Nature, 2005,436(7052):793-800.
doi: 10.1038/nature03895 pmid: 16100779 |
| [6] |
RGP. The 3,000 rice genomes project. GigaScience, 2014,3:7.
doi: 10.1186/2047-217X-3-7 pmid: 24872877 |
| [7] |
Milner SG, Jost M, Taketa S, Mazón ER, Himmelbach A, Oppermann M, Weise S, Knüpffer H, Basterrechea M, König P, Schüler D, Sharma R, Pasam RK, Rutten T, Guo GG, Xu DD, Zhang J, Herren G, Müller T, Krattinger SG, Keller B, Jiang Y, González MY, Zhao YS, Habekuß A, Färber S, Ordon F, Lange M, Börner A, Graner A, Reif JC, Scholz U, Mascher M, Stein N . Genebank genomics highlights the diversity of a global barley collection. Nat Genet, 2019,51(2):319-326.
doi: 10.1038/s41588-018-0266-x pmid: 30420647 |
| [8] |
Sayers EW, Cavanaugh M, Clark K, Ostell J, Pruitt KD, Karsch-Mizrachi I . GenBank. Nucleic Acids Res, 2019,47(D1):D94-D99.
doi: 10.1093/nar/gky989 pmid: 30365038 |
| [9] |
Madeira F, Park YM, Lee J, Buso N, Gur T, Madhusoodanan N, Basutkar P, Tivey ARN, Potter SC, Finn RD, Lopez R . The EMBL-EBI search and sequence analysis tools APIs in 2019. Nucleic Acids Res, 2019,47(W1):W636-W641.
doi: 10.1093/nar/gkz268 pmid: 30976793 |
| [10] |
Kodama Y, Mashima J, Kosuge T, Ogasawara O . DDBJ update: the Genomic Expression Archive (GEA) for functional genomics data. Nucleic Acids Res, 2019,47(D1):D69-D73.
doi: 10.1093/nar/gky1002 pmid: 30357349 |
| [11] |
Rigden DJ, Fernández XM . The 2018 Nucleic Acids Research database issue and the online molecular biology database collection. Nucleic Acids Res, 2018,46(D1):D1-D7.
doi: 10.1093/nar/gkx1235 pmid: 29316735 |
| [12] |
Members SIB . The SIB Swiss Institute of Bioinformatics’ resources: focus on curated databases. Nucleic Acids Res, 2016,44(D1):D27-D37.
doi: 10.1093/nar/gkv1310 pmid: 26615188 |
| [13] |
Kanehisa M, Furumichi M, Tanabe M, Sato Y, Morishima K . KEGG: new perspectives on genomes, pathways, diseases and drugs. Nucleic Acids Res, 2017,45(D1):D353-D361.
doi: 10.1093/nar/gkw1092 pmid: 27899662 |
| [14] |
Cochrane G, Karsch-Mizrachi I, Takagi T , International Nucleotide Sequence Database Collaboration. The international nucleotide sequence database collaboration. Nucleic Acids Res, 2016,46(D1):D48-D51.
doi: 10.1093/nar/gkx1097 pmid: 29190397 |
| [15] |
Wang J, Wang W, Li RQ, Li YR, Tian G, Goodman L, Fan W, Zhang JQ, Li J, Zhang JB, Guo TR, Feng BX, Li H, Lu Y, Fang XD, Liang HQ, Du ZL, Li D, Zhao YQ, Hu YJ, Yang ZZ, Zheng HC, Hellmann I, Inouye M, Pool J, Yi X, Zhao J, Duan JJ, Zhou Y, Qin JJ, Ma LJ, Li GQ, Yang ZT, Zhang GJ, Yang B, Yu C, Liang F, Li WJ, Li SC, Li DW, Ni PX, Ruan J, Li QB, Zhu HM, Liu DY, Lu ZK, Li N, Guo GW, Zhang JG, Ye J, Fang L, Hao Q, Chen Q, Liang Y, Su YY, San A, Ping C, Yang S, Chen F, Li L, Zhou K, Zheng HK, Ren YY, Yang L, Gao Y, Yang GH, Li Z, Feng XL, Kristiansen K, Wong GKS, Nielsen R, Durbin R, Bolund L, Zhang XQ, Li SG, Yang HM, Wang J . The diploid genome sequence of an Asian individual. Nature, 2008,456(7218):60-65.
doi: 10.1038/nature07484 pmid: 18987735 |
| [16] |
Li RQ, Fan W, Tian G, Zhu HM, He L, Cai J, Huang QF, Cai QL, Li B, Bai YQ, Zhang ZH, Zhang YP, Wang W, Li J, Wei FW, Li H, Jian M, Li JW, Zhang ZL, Nielsen R, Li DW, Gu WJ, Yang ZT, Xuan ZL, Ryder OA, Leung FCC, Zhou Y, Cao JJ, Sun X, Fu YG, Fang XD, Guo XS, Wang B, Hou R, Shen FJ, Mu B, Ni PX, Lin RM, Qian WB, Wang GD, Yu C, Nie WH, Wang JH, Wu ZG, Liang HQ, Min JM, Wu Q, Cheng SF, Ruan J, Wang MW, Shi ZB, Wen M, Liu BH, Ren XL, Zheng HS, Dong D, Cook K, Shan G, Zhang H, Kosiol C, Xie XY, Lu ZH, Zheng HC, Li YR, Steiner CC, Tsan-Yuk Lam T, Lin SY, Zhang QH, Li GQ, Tian J, Gong TM, Liu HD, Zhang DJ, Fang L, Ye C, Zhang JB, Hu WB, Xu AL, Ren YY, Zhang GJ, Bruford MW, Li QB, Ma LJ, Guo YR, An N, Hu YJ, Zheng Y, Shi YY, Li ZQ, Liu Q, Chen YL, Zhao J, Qu N, Zhao SC, Tian F, Wang XL, Wang HY, Xu LZ, Liu X, Vinar T, Wang YJ, Lam TW, Yiu SM, Liu SP, Zhang HM, Li DS, Huang Y, Wang X, Yang GH, Jiang Z, Wang JY, Qin N, Li L, Li JX, Bolund L, Kristiansen K, Wong GKS, Olson M, Zhang XQ, Li SG, Yang HM, Wang J, Wang J. The sequence and de novo assembly of the giant panda genome. Nature, 2010,463(7279):311-317.
doi: 10.1038/nature08696 pmid: 20010809 |
| [17] |
Members NGDC . Database resources of the national genomics data center in 2020. Nucleic Acids Res, 2020,48(D1):D24-D33.
doi: 10.1093/nar/gkz913 pmid: 31702008 |
| [18] | Ma YK, Bao YM . Prospects for national biological big data centers. Hereditas(Beijing), 2018,40(11):938-943. |
| 马英克, 鲍一明 . 国家级生物大数据中心展望. 遗传, 2018,40(11):938-943. | |
| [19] |
Wang YQ, Song FH, Zhu JW, Zhang SS, Yang YD, Chen TT, Tang BX, Dong LL, Ding N, Zhang Q, Bai ZX, Dong XN, Chen HX, Sun MY, Zhai S, Sun YB, Yu L, Lan L, Xiao JF, Fang XD, Lei HX, Zhang Z, Zhao WM . GSA: genome sequence archive. Genomics Proteomics Bioinformatics, 2017,15(1):14-18.
doi: 10.1016/j.gpb.2017.01.001 pmid: 28387199 |
| [20] | Zhang YS, Xia L, Sang J, Li M, Liu L, Li MW, Niu GY, Cao JB, Teng XF, Zhou Q, Zhang, Z. The BIG Data Center's database resources. Hereditas(Beijing), 2018,40(11):1039-1043. |
| 张源笙, 夏琳, 桑健, 李漫, 刘琳, 李萌伟, 牛广艺, 曹佳宝, 滕徐菲, 周晴, 章张 . 生命与健康大数据中心资源. 遗传, 2018,40(11):1039-1043. | |
| [21] | Zhang SS, Chen TT, Zhu JW, Zhou Q, Chen X, Wang YQ, Zhao WM . GSA: genome sequence archive. Hereditas (Beijing), 2018,40(11):1044-1047. |
| 张思思, 陈婷婷, 朱军伟, 周晴, 陈旭, 王彦青, 赵文明 . GSA: 组学原始数据归档库. 遗传, 2018,40(11):1044-1047. | |
| [22] |
Shi WY, Qi HY, Sun QL, Fan GM, Liu SJ, Wang J, Zhu BL, Liu HW, Zhao FQ, Wang XC, Hu XX, Li W, Liu J, Tian Y, Wu LH, Ma JC,. gcMeta: a Global Catalogue of Metagenomics platform to support the archiving, standardization and analysis of microbiome data. Nucleic Acids Res, 2019,47(D1):D637-D648.
doi: 10.1093/nar/gky1008 pmid: 30365027 |
| [23] |
Wu LH, Sun QL, Sugawara H, Yang S, Zhou YG, McCluskey K, Vasilenko A, Suzuki KI, Ohkuma M, Lee Y, Robert V, Ingsriswang S, Guissart F, Philippe D, Ma JC. Global catalogue of microorganisms (gcm): a comprehensive database and information retrieval, analysis, and visualization system for microbial resources. BMC Genomics, 2013,14:933.
doi: 10.1186/1471-2164-14-933 pmid: 24377417 |
| [24] |
Zhang GJ . Bird sequencing project takes off. Nature, 2015,522(7554):34.
doi: 10.1038/522034d pmid: 26040883 |
| [25] | Fan GY, Song Y, Huang XY, Yang LD, Zhang SY, Zhang MQ, Yang XW, Chang Y, Zhang H, Li YX, Liu SS, Yu LL, Seim I, Feng CG, Wang W, Wang K, Wang J, Xu X, Yang HM, Chen NS, Liu X, He SP . Initial data release and announcement of the Fish10K: Fish 10,000 Genomes Project. bioRxiv, 2019,787028. |
| [26] |
Initiative OTPT . One thousand plant transcriptomes and the phylogenomics of green plants. Nature, 2019,574:679-685.
doi: 10.1038/s41586-019-1693-2 pmid: 31645766 |
| [27] | Paskin N . Digital object identifier (DOI®) system. Encyclopedia of Library and Information Sciences, 2010,3:1586-1592. |
| [28] |
Smigielski EM, Sirotkin K, Ward M, Sherry ST,. dbSNP: a database of single nucleotide polymorphisms. Nucleic Acids Res, 2000,28(1):352-355.
doi: 10.1093/nar/28.1.352 pmid: 10592272 |
| [29] |
Landrum MJ, Lee JM, Benson M, Brown G, Chao C, Chitipiralla S, Gu BS, Hart J, Hoffman D, Hoover J, Jang WH, Katz KK, Ovetsky M, Riley G, Sethi A, Tully R, Villamarin-Salomon R, Rubinstein W, Maglott DR . ClinVar: public archive of interpretations of clinically relevant variants. Nucleic Acids Res, 2016,44(D1):D862-D868.
doi: 10.1093/nar/gkv1222 pmid: 26582918 |
| [30] |
Consortium U . UniProt: a worldwide hub of protein knowledge. Nucleic Acids Res, 2019,47(D1):D506-D515.
doi: 10.1093/nar/gky1049 pmid: 30395287 |
| [31] |
Pruitt KD, Tatusova T, Maglott DR . NCBI reference sequences (RefSeq): a curated non-redundant sequence database of genomes, transcripts and proteins. Nucleic Acids Res, 2007,35:D61-D65.
doi: 10.1093/nar/gkl842 pmid: 17130148 |
| [32] |
Barrett T, Clark K, Gevorgyan R, Gorelenkov V, Gribov E, Karsch-Mizrachi I, Kimelman M, Pruitt KD, Resenchuk S, Tatusova T, Yaschenko E, Ostell J . BioProject and BioSample databases at NCBI: facilitating capture and organization of metadata. Nucleic Acids Res, 2012,40(D1):D57-D63.
doi: 10.1093/nar/gkr1163 |
| [33] |
Kodama Y, Shumway M, Leinonen R . The Sequence Read Archive: explosive growth of sequencing data. Nucleic Acids Res, 2012,40:D54-D56.
doi: 10.1093/nar/gkr854 pmid: 22009675 |
| [34] |
Kitts PA, Church DM, Thibaud-Nissen F, Choi J, Hem V, Sapojnikov V, Smith RG, Tatusova T, Xiang C, Zherikov A, DiCuccio M, Murphy TD, Pruitt KD, Kimchi A. Assembly: a resource for assembled genomes at NCBI. Nucleic Acids Res, 2016,44:D73-D80.
doi: 10.1093/nar/gkv1226 pmid: 26578580 |
| [35] | Gormley C, Tong Z . Elasticsearch: the definitive guide: a distributed real-time search and analytics engine. “O'Reilly Media, Inc.”, 2015. |
| [36] |
Federhen S . The NCBI taxonomy database. Nucleic Acids Res, 2012,40:D136-D143.
doi: 10.1093/nar/gkr1178 pmid: 22139910 |
| [37] |
Marc DT, Khairat SS,. Medical Subject Headings(MeSH) for indexing and retrieving open-source healthcare data. Stud Health Technol Inform, 2014,202:157-160.
pmid: 25000040 |
| [1] | 雷常贵, 贾学渊, 孙文靖. 基于癌症基因组图谱计划多组学数据构建胶质母细胞瘤六基因预后模型[J]. 遗传, 2021, 43(7): 665-679. |
| [2] | 张思思, 陈旭, 陈婷婷, 朱军伟, 唐碧霞, 王安可, 董丽莉, 张哲文, 孙艳玲, 俞彩霞, 翟爽, 孙玉彬, 陈焕新, 杜政霖, 肖景发, 章张, 鲍一明, 王彦青, 赵文明. GSA-Human:人类遗传资源数据管理的公共系统[J]. 遗传, 2021, 43(10): 988-993. |
| [3] | 赵文明, 宋述慧, 陈梅丽, 邹东, 马利娜, 马英克, 李茹姣, 郝丽丽, 李翠萍, 田东梅, 唐碧霞, 王彦青, 朱军伟, 陈焕新, 章张, 薛勇彪, 鲍一明. 2019新型冠状病毒信息库[J]. 遗传, 2020, 42(2): 212-221. |
| [4] | 张源笙,夏琳,桑健,李漫,刘琳,李萌伟,牛广艺,曹佳宝,滕徐菲,周晴,章张. 生命与健康大数据中心资源[J]. 遗传, 2018, 40(11): 1039-1043. |
| [5] | 张思思,陈婷婷,朱军伟,周晴,陈旭,王彦青,赵文明. GSA:组学原始数据归档库[J]. 遗传, 2018, 40(11): 1044-1047. |
| 阅读次数 | ||||||
|
全文 |
|
|||||
|
摘要 |
|
|||||

www.chinagene.cn
备案号:京ICP备09063187号-4
总访问:,今日访问:,当前在线:
