
遗传 ›› 2024, Vol. 46 ›› Issue (3): 183-198.doi: 10.16288/j.yczz.23-321
刘羽诚1( ), 申妍婷1, 田志喜1,2()
), 申妍婷1, 田志喜1,2()
收稿日期:2023-12-29
修回日期:2024-02-09
出版日期:2024-03-20
发布日期:2024-02-22
通讯作者:
田志喜
E-mail:ychliu@genetics.ac.cn;zxtian@genetics.ac.cn
作者简介:刘羽诚,副研究员,研究方向:大豆比较基因组学。E-mail: ychliu@genetics.ac.cn。2016—2020年就读于中国科学院遗传与发育生物学研究所,在田志喜课题组攻读博士学位;2021—2023年在该课题组开展博士后工作;2023年至今任中国科学院遗传与发育生物学研究所副研究员,从事大豆功能基因组学、比较基因组学、大数据挖掘与数据库开发相关研究。博士期间,开展大豆泛基因组工作,完成26个大豆种质的高质量参考基因组,在植物中创造性实践了图泛基因组构建策略,系统阐释了染色体结构变异在大豆演化/驯化过程中的作用,为后续泛基因组研究提供了经典的思路和范例。获得“博士后创新人才计划”、“中国科学院稳定支持青年团队”项目资助;主持国家自然科学基金委青年科学基金项目。博士论文《大豆泛基因组研究》荣获2023年中国科学院优秀博士生论文。
基金资助:
Yucheng Liu1(), Yanting Shen1, Zhixi Tian1,2()
Received:2023-12-29
Revised:2024-02-09
Published:2024-03-20
Online:2024-02-22
Contact:
Zhixi Tian
E-mail:ychliu@genetics.ac.cn;zxtian@genetics.ac.cn
Supported by:摘要:
人工驯化为农业发展提供了原始驱动力,也深刻地改变了许多动植物的遗传背景。伴随组学大数据理论和技术体系的发展,作物基因组研究已迈入泛基因组时代。借助泛基因组的研究思路,通过多基因组间的比较和整合,能够评估物种遗传信息上界和下界,认知物种的遗传多样性全貌。此外,将泛基因组与染色体大尺度结构变异、群体高通量测序及多层次组学数据相结合,可以进行更为深入的性状-遗传机制解析。大豆(Glycine max (L.) Merr.)是重要的粮油经济作物,大豆产能关乎国家粮食安全。对大豆遗传背景形成、重要农艺性状关键位点的解析,是实现更高效的大豆育种改良的前提。本文首先对泛基因组学的核心问题进行了阐述,解释了从头组装/比对组装、迭代式组装和图基因组等泛基因组研究策略的演变历程和各自特征;接着对作物泛基因组研究的热点问题进行了概括,并且以大豆为例详细阐释了包括类群选择、泛基因组构建、数据挖掘等方面在内的泛基因组研究的开展思路,着重说明染色体结构变异在大豆演化/驯化历程中的贡献及其在农艺性状遗传基础挖掘上的价值;最后讨论了图泛基因组在数据整合、结构变异计算方面的应用前景。本文对作物泛基因组未来的发展趋势进行了展望,以期为作物基因组学及数据科学研究提供参考。
刘羽诚, 申妍婷, 田志喜. 大豆泛基因组研究进展[J]. 遗传, 2024, 46(3): 183-198.
Yucheng Liu, Yanting Shen, Zhixi Tian. Frontiers of soybean pan-genome studies[J]. Hereditas(Beijing), 2024, 46(3): 183-198.
表1
植物泛基因组研究实例汇总"
| 类群 | 发表年份 | 样品数 | 测序方式 | 泛基因组构建策略 | 参考文献 |
|---|---|---|---|---|---|
| 拟南芥(Arabidopsis thaliana) | 2011 | 18 | 二代测序 | 迭代组装+从头组装 | [ |
| 野生大豆(Glycine soja) | 2014 | 7 | 二代测序 | 从头组装 | [ |
| 甘蓝(Brassica oleracea) | 2016 | 9 | 二代测序 | 迭代组装 | [ |
| 苜蓿(Medicago truncatula) | 2017 | 15 | 二代测序 | 从头组装 | [ |
| 二穗短柄草(Brachypodium distachyon) | 2017 | 54 | 二代测序 | 从头组装 | [ |
| 水稻(Oryza sativa) | 2018 | 3010 | 二代测序+三代测序 | 比对组装 | [ |
| 野生及栽培水稻(O. rufipogon, O. sativa) | 2018 | 66 | 二代测序 | 比对组装 | [ |
| 水稻属及亲缘物种(Oryza, Leersia) | 2018 | 13 | 三代测序+二代测序 | 从头组装 | [ |
| 辣椒属(Capsicum) | 2018 | 168 | 二代测序 | 比对组装 | [ |
| 芝麻(Sesamum indicum) | 2018 | 5 | 二代测序 | 比对组装 | [ |
| 番茄及野生亲缘种(Solanum section Lycopersicon) | 2019 | 725 | 二代测序 | 比对组装 | [ |
| 向日葵(Helianthus annuus) | 2019 | 287 | 二代测序 | 比对组装 | [ |
| 油菜(Brassica napus) | 2020 | 8 | 三代测序 | 从头组装 | [ |
| 野生及栽培大豆(Glycine subgenus Soja) | 2020 | 29 | 三代测序 | 从头组装+图基因组 | [ |
| 大麦(Hordeum vulgare) | 2020 | 20 | 二代测序+三代测序 | 从头组装 | [ |
| 番茄及野生亲缘种(Solanum section Lycopersicon) | 2020 | 14 | 二代测序+三代测序 | 比对组装(泛结构变异) | [ |
| 鹰嘴豆(Cicer arietinum) | 2021 | 3366 | 二代测序 | 比对组装 | [ |
| 棉花及亲缘种(Gossypium) | 2021 | 1961 | 二代测序 | 比对组装 | [ |
| 野生及栽培高粱(Sorghum bicolor) | 2021 | 13 | 三代测序 | 从头组装 | [ |
| 玉米(Zea may) | 2021 | 26 | 三代测序 | 从头组装 | [ |
| 水稻(O. sativa) | 2021 | 33 | 三代测序 | 从头组装+图基因组 | [ |
| 野生及栽培萝卜(Raphanus) | 2021 | 11 | 三代测序 | 从头组装+图基因组 | [ |
| 黄瓜 (Cucumis sativus) | 2022 | 12 | 三代测序 | 从头组装+图基因组 | [ |
| 水稻属(Oryza) | 2022 | 251 | 三代测序 | 从头组装+图基因组 | [ |
| 棉花属(Gossypium) | 2022 | 10 | 三代测序 | 从头组装+图基因组 | [ |
| 多年生大豆(Glycine subgenus Glycine) | 2022 | 6 | 三代测序 | 从头组装 | [ |
| 野生及栽培马铃薯(Solanum section Petota) | 2022 | 44 | 三代测序 | 从头组装 | [ |
| 番茄(Solanum lycopersicum) | 2022 | 32 | 三代测序 | 从头组装+图基因组 | [ |
| 野生及栽培谷子(Setaria) | 2023 | 110 | 三代测序 | 从头组装+图基因组 | [ |
| 茶(Camellia sinensis) | 2023 | 22 | 三代测序 | 从头组装+图基因组 | [ |
| 柑橘属(Citrus) | 2023 | 12 | 三代测序 | 从头组装+图基因组 | [ |
| 番茄及野生亲缘种(Solanum section Lycopersicon) | 2023 | 13 | 三代测序 | 从头组装+图基因组 | [ |
| 玉米(Z. mays) | 2023 | 12 | 三代测序 | 从头组装 | [ |
| 野生及栽培黍(Panicum miliaceum) | 2023 | 32 | 三代测序 | 从头组装+图基因组 | [ |
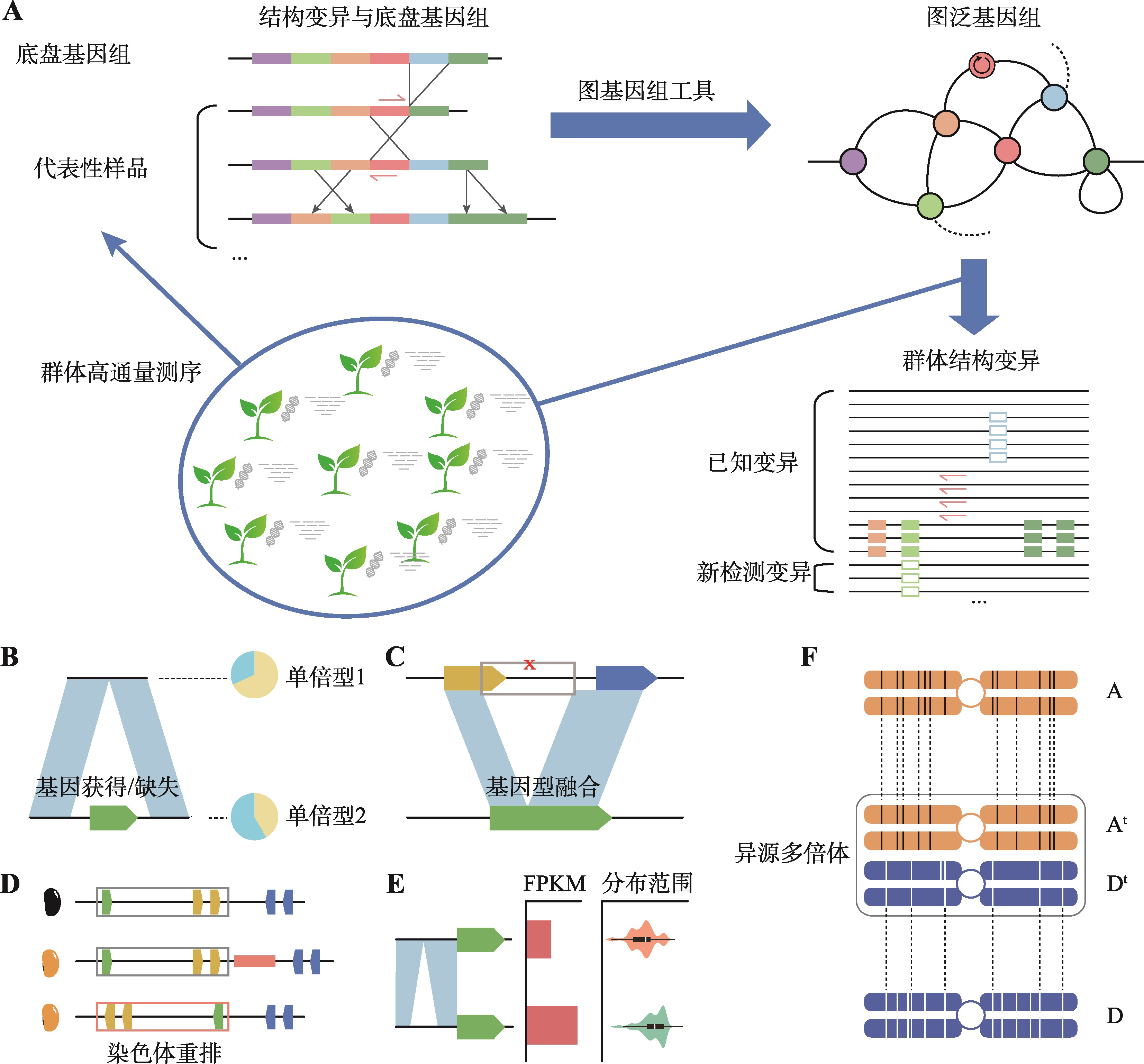
图1
作物泛基因组研究策略及认知 A:图泛基因组研究基本流程,包括群体测序筛选代表性样品、结构变异分析、图泛基因组构建、群体结构变异检测等;B~E:泛基因组视角下的大豆农艺性状、演化历程遗传机制认知,包括基因获得/缺失与种皮亮度(B)、基因融合与E3基因多态性(C)、染色体重排与种皮颜色(D)、结构变异对基因表达调控与种质分布(E);F:异源多倍体大豆的冗余基因丢失与亚基因组偏好性。"
| [1] |
Clark JW, Donoghue PCJ. Whole-genome duplication and plant macroevolution. Trends Plant Sci, 2018, 23(10): 933-945.
doi: S1360-1385(18)30159-6 pmid: 30122372 |
| [2] |
Danilevicz MF, Tay Fernandez CG, Marsh JI, Bayer PE, Edwards D. Plant pangenomics: approaches, applications and advancements. Curr Opin Plant Biol, 2020, 54: 18-25.
doi: S1369-5266(19)30120-7 pmid: 31982844 |
| [3] |
Saxena RK, Edwards D, Varshney RK. Structural variations in plant genomes. Brief Funct Genomics, 2014, 13(4): 296-307.
doi: 10.1093/bfgp/elu016 pmid: 24907366 |
| [4] |
Golicz AA, Batley J, Edwards D. Towards plant pangenomics. Plant Biotechnol J, 2016, 14(4): 1099-1105.
doi: 10.1111/pbi.12499 pmid: 26593040 |
| [5] |
Tao YF, Zhao XR, Mace E, Henry R, Jordan D. Exploring and exploiting pan-genomics for crop improvement. Mol Plant, 2019, 12(2): 156-169.
doi: S1674-2052(18)30383-6 pmid: 30594655 |
| [6] |
Tettelin H, Masignani V, Cieslewicz MJ, Donati C, Medini D, Ward NL, Angiuoli SV, Crabtree J, Jones AL, Durkin AS, Deboy RT, Davidsen TM, Mora M, Scarselli M, Margarit y Ros I, Peterson JD, Hauser CR, Sundaram JP, Nelson WC, Madupu R, Brinkac LM, Dodson RJ, Rosovitz MJ, Sullivan SA, Daugherty SC, Haft DH, Selengut J, Gwinn ML, Zhou LW, Zafar N, Khouri H, Radune D, Dimitrov G, Watkins K, O'Connor KJB, Smith S, Utterback TR, White O, Rubens CE, Grandi G, Madoff LC, Kasper DL, Telford JL, Wessels MR, Rappuoli R, Fraser CM. Genome analysis of multiple pathogenic isolates of Streptococcus agalactiae: implications for the microbial “pan-genome”. Proc Natl Acad Sci USA, 2005, 102(39): 13950-13955.
doi: 10.1073/pnas.0506758102 pmid: 16172379 |
| [7] | Baker M. De novo genome assembly: what every biologist should know. Nat Methods, 2012, 9(4): 333-337. |
| [8] |
Edger PP, Poorten TJ, VanBuren R, Hardigan MA, Colle M, McKain MR, Smith RD, Teresi SJ, Nelson ADL, Wai CM, Alger EI, Bird KA, Yocca AE, Pumplin N, Ou SJ, Ben-Zvi G, Brodt A, Baruch K, Swale T, Shiue L, Acharya CB, Cole GS, Mower JP, Childs KL, Jiang N, Lyons E, Freeling M, Puzey JR, Knapp SJ. Origin and evolution of the octoploid strawberry genome. Nat Genet, 2019, 51(3): 541-547.
doi: 10.1038/s41588-019-0356-4 pmid: 30804557 |
| [9] |
Huang SF, Kang MJ, Xu AL. HaploMerger2: rebuilding both haploid sub-assemblies from high-heterozygosity diploid genome assembly. Bioinformatics, 2017, 33(16): 2577-2579.
doi: 10.1093/bioinformatics/btx220 pmid: 28407147 |
| [10] |
Zhang JS, Zhang XT, Tang HB, Zhang Q, Hua XT, Ma XK, Zhu F, Jones T, Zhu XG, Bowers J, Wai CM, Zheng CF, Shi Y, Chen S, Xu XM, Yue JJ, Nelson DR, Huang LX, Li Z, Xu HM, Zhou D, Wang YJ, Hu WC, Lin JS, Deng YJ, Pandey N, Mancini M, Zerpa D, Nguyen JK, Wang LM, Yu L, Xin YH, Ge LF, Arro J, Han JO, Chakrabarty S, Pushko M, Zhang WP, Ma YH, Ma PP, Lv MJ, Chen FM, Zheng GY, Xu JS, Yang ZH, Deng F, Chen XQ, Liao ZY, Zhang XX, Lin ZC, Lin H, Yan HS, Kuang Z, Zhong WM, Liang PP, Wang GF, Yuan Y, Shi JX, Hou JX, Lin JX, Jin JJ, Cao PJ, Shen QC, Jiang Q, Zhou P, Ma YY, Zhang XD, Xu RR, Liu J, Zhou YM, Jia HF, Ma Q, Qi R, Zhang ZL, Fang JP, Fang HK, Song JJ, Wang MJ, Dong GR, Wang G, Chen Z, Ma T, Liu H, Dhungana SR, Huss SE, Yang XP, Sharma A, Trujillo JH, Martinez MC, Hudson M, Riascos JJ, Schuler M, Chen LQ, Braun DM, Li L, Yu QY, Wang JP, Wang K, Schatz MC, Heckerman D, Van Sluys MA, Souza GM, Moore PH, Sankoff D, VanBuren R, Paterson AH, Nagai C, Ming R. Allele-defined genome of the autopolyploid sugarcane Saccharum spontaneum L. Nat Genet, 2018, 50(11): 1565-1573.
doi: 10.1038/s41588-018-0237-2 |
| [11] |
Sherman RM, Salzberg SL. Pan-genomics in the human genome era. Nat Rev Genet, 2020, 21(4): 243-254.
doi: 10.1038/s41576-020-0210-7 pmid: 32034321 |
| [12] |
Ni LB, Liu YC, Ma X, Liu TF, Yang XY, Wang Z, Liang QJ, Liu SL, Zhang M, Wang Z, Shen YT, Tian ZX. Pan-3D genome analysis reveals structural and functional differentiation of soybean genomes. Genome Biol, 2023, 24(1): 12.
doi: 10.1186/s13059-023-02854-8 pmid: 36658660 |
| [13] | Hirsch CN, Foerster JM, Johnson JM, Sekhon RS, Muttoni G, Vaillancourt B, Peñagaricano F, Lindquist E, Pedraza MA, Barry K, de Leon N, Kaeppler SM, Buell CR. Insights into the maize pan-genome and pan-transcriptome. Plant Cell, 2014, 26(1): 121-135. |
| [14] |
Vernikos G, Medini D, Riley DR, Tettelin H. Ten years of pan-genome analyses. Curr Opin Microbiol, 2015, 23: 148-154.
doi: 10.1016/j.mib.2014.11.016 pmid: 25483351 |
| [15] |
De Coster W, Weissensteiner MH, Sedlazeck FJ.Towards population-scale long-read sequencing. Nat Rev Genet, 2021, 22(9): 572-587.
doi: 10.1038/s41576-021-00367-3 pmid: 34050336 |
| [16] |
Gordon SP, Contreras-Moreira B, Woods DP, Des Marais DL, Burgess D, Shu SQ, Stritt C, Roulin AC, Schackwitz W, Tyler L, Martin J, Lipzen A, Dochy N, Phillips J, Barry K, Geuten K, Budak H, Juenger TE, Amasino R, Caicedo AL, Goodstein D, Davidson P, Mur LAJ, Figueroa M, Freeling M, Catalan P, Vogel JP. Extensive gene content variation in the Brachypodium distachyon pan-genome correlates with population structure. Nat Commun, 2017, 8(1): 2184.
doi: 10.1038/s41467-017-02292-8 pmid: 29259172 |
| [17] |
Li YH, Zhou GY, Ma JX, Jiang WK, Jin LG, Zhang ZH, Guo Y, Zhang JB, Sui Y, Zheng LT, Zhang SS, Zuo QY, Shi XH, Li YF, Zhang WK, Hu YY, Kong GY, Hong HL, Tan B, Song J, Liu ZX, Wang YS, Ruan H, Yeung CKL, Liu J, Wang HL, Zhang LJ, Guan RX, Wang KJ, Li WB, Chen SY, Chang RZ, Jiang Z, Jackson SA, Li RQ, Qiu LJ. De novo assembly of soybean wild relatives for pan-genome analysis of diversity and agronomic traits. Nat Biotechnol, 2014, 32(10): 1045-1052.
doi: 10.1038/nbt.2979 |
| [18] |
Stein JC, Yu Y, Copetti D, Zwickl DJ, Zhang L, Zhang CJ, Chougule K, Gao DY, Iwata A, Goicoechea JL, Wei SR, Wang J, Liao Y, Wang MH, Jacquemin J, Becker C, Kudrna D, Zhang JW, Londono CEM, Song X, Lee S, Sanchez P, Zuccolo A, Ammiraju JSS, Talag J, Danowitz A, Rivera LF, Gschwend AR, Noutsos C, Wu CC, Kao SM, Zeng JW, Wei FJ, Zhao Q, Feng Q, El Baidouri M, Carpentier MC, Lasserre E, Cooke R, da Rosa Farias D, da Maia LC, Dos Santos RS, Nyberg KG, McNally KL, Mauleon R, Alexandrov N, Schmutz J, Flowers D, Fan CZ, Weigel D, Jena KK, Wicker T, Chen MS, Han B, Henry R, Hsing YC, Kurata N, de Oliveira AC, Panaud O, Jackson SA, Machado CA, Sanderson MJ, Long MY, Ware D, Wing RA.Genomes of 13 domesticated and wild rice relatives highlight genetic conservation, turnover and innovation across the genus Oryza. Nat Genet, 2018, 50(2): 285-296.
doi: 10.1038/s41588-018-0040-0 pmid: 29358651 |
| [19] |
Gao L, Gonda I, Sun HH, Ma QY, Bao K, Tieman DM, Burzynski-Chang EA, Fish TL, Stromberg KA, Sacks GL, Thannhauser TW, Foolad MR, Diez MJ, Blanca J, Canizares J, Xu YM, van der Knaap E, Huang SW, Klee HJ, Giovannoni JJ, Fei ZQ. The tomato pan-genome uncovers new genes and a rare allele regulating fruit flavor. Nat Genet, 2019, 51(6): 1044-1051.
doi: 10.1038/s41588-019-0410-2 pmid: 31086351 |
| [20] |
Hübner S, Bercovich N, Todesco M, Mandel JR, Odenheimer J, Ziegler E, Lee JS, Baute GJ, Owens GL, Grassa CJ, Ebert DP, Ostevik KL, Moyers BT, Yakimowski S, Masalia RR, Gao LX, Ćalić I, Bowers JE, Kane NC, Swanevelder DZH, Kubach T, Muños S, Langlade NB, Burke JM, Rieseberg LH. Sunflower pan-genome analysis shows that hybridization altered gene content and disease resistance. Nat Plants, 2019, 5(1): 54-62.
doi: 10.1038/s41477-018-0329-0 pmid: 30598532 |
| [21] | Wang WS, Mauleon R, Hu ZQ, Chebotarov D, Tai SS, Wu ZC, Li M, Zheng TQ, Fuentes RR, Zhang F, Mansueto L, Copetti D, Sanciangco M, Palis KC, Xu JL, Sun C, Fu BY, Zhang HL, Gao YM, Zhao XQ, Shen F, Cui X, Yu H, Li ZC, Chen ML, Detras J, Zhou YL, Zhang XY, Zhao Y, Kudrna D, Wang CC, Li R, Jia B, Lu JY, He XC, Dong ZT, Xu JB, Li YH, Wang M, Shi JX, Li J, Zhang DB, Lee S, Hu WS, Poliakov A, Dubchak I, Ulat VJ, Borja FN, Mendoza JR, Ali J, Li J, Gao Q, Niu YC, Yue Z, Naredo MEB, Talag J, Wang XQ, Li JJ, Fang XD, Yin Y, Glaszmann JC, Zhang JW, Li JY, Hamilton RS, Wing RA, Ruan J, Zhang GY, Wei CC, Alexandrov N, McNally KL, Li ZK, Leung H. Genomic variation in 3,010 diverse accessions of Asian cultivated rice. Nature, 2018, 557(7703): 43-49. |
| [22] |
Golicz AA, Bayer PE, Barker GC, Edger PP, Kim H, Martinez PA, Chan CKK, Severn-Ellis A, McCombie WR, Parkin IAP, Paterson AH, Pires JC, Sharpe AG, Tang HB, Teakle GR, Town CD, Batley J, Edwards D. The pangenome of an agronomically important crop plant Brassica oleracea. Nat Commun, 2016, 7: 13390.
doi: 10.1038/ncomms13390 pmid: 27834372 |
| [23] |
Iqbal Z, Caccamo M, Turner I, Flicek P, McVean G. De novo assembly and genotyping of variants using colored de Bruijn graphs. Nat Genet, 2012, 44(2): 226-232.
doi: 10.1038/ng.1028 |
| [24] |
Audano PA, Sulovari A, Graves-Lindsay TA, Cantsilieris S, Sorensen M, Welch AE, Dougherty ML, Nelson BJ, Shah A, Dutcher SK, Warren WC, Magrini V, McGrath SD, Li YI, Wilson RK, Eichler EE. Characterizing the major structural variant alleles of the human genome. Cell, 2019, 176(3): 663-675.
doi: S0092-8674(18)31633-7 pmid: 30661756 |
| [25] |
Eggertsson HP, Kristmundsdottir S, Beyter D, Jonsson H, Skuladottir A, Hardarson MT, Gudbjartsson DF, Stefansson K, Halldorsson BV, Melsted P. GraphTyper 2 enables population-scale genotyping of structural variation using pangenome graphs. Nat Commun, 2019, 10(1): 5402.
doi: 10.1038/s41467-019-13341-9 pmid: 31776332 |
| [26] |
Garrison E, Sirén J, Novak AM, Hickey G, Eizenga JM, Dawson ET, Jones W, Garg S, Markello C, Lin MF, Paten B, Durbin R. Variation graph toolkit improves read mapping by representing genetic variation in the reference. Nat Biotechnol, 2018, 36(9): 875-879.
doi: 10.1038/nbt.4227 pmid: 30125266 |
| [27] |
Marcus S, Lee H, Schatz MC. SplitMEM: a graphical algorithm for pan-genome analysis with suffix skips. Bioinformatics, 2014, 30(24): 3476-3483.
doi: 10.1093/bioinformatics/btu756 pmid: 25398610 |
| [28] |
Zhao YB, Jia XM, Yang JH, Ling YC, Zhang Z, Yu J, Wu JY, Xiao JF. PanGP: a tool for quickly analyzing bacterial pan-genome profile. Bioinformatics, 2014, 30(9): 1297-1299.
doi: 10.1093/bioinformatics/btu017 pmid: 24420766 |
| [29] |
Sirén J, Monlong J, Chang X, Novak AM, Eizenga JM, Markello C, Sibbesen JA, Hickey G, Chang PC, Carroll A, Gupta N, Gabriel S, Blackwell TW, Ratan A, Taylor KD, Rich SS, Rotter JI, Haussler D, Garrison E, Paten B. Pangenomics enables genotyping of known structural variants in 5202 diverse genomes. Science, 2021, 374(6574): abg8871.
doi: 10.1126/science.abg8871 |
| [30] |
Guarracino A, Heumos S, Nahnsen S, Prins P, Garrison E. ODGI: understanding pangenome graphs. Bioinformatics, 2022, 38(13): 3319-3326.
doi: 10.1093/bioinformatics/btac308 pmid: 35552372 |
| [31] | Garrison E, Guarracino A, Heumos S, Villani F, Bao ZG, Tattini L, Hagmann J, Vorbrugg S, Marco-Sola S, Kubica C, Ashbrook DG, Thorell K, Rusholme-Pilcher RL, Liti G, Rudbeck E, Nahnsen S, Yang ZY, Moses MN, Nobrega FL, Wu Y, Chen H, de Ligt J, Sudmant PH, Soranzo N, Colonna V, Williams RW, Prins P. Building pangenome graphs. bioRxiv, 2023. |
| [32] |
Kim D, Paggi JM, Park C, Bennett C, Salzberg SL. Graph-based genome alignment and genotyping with HISAT2 and HISAT-genotype. Nat Biotechnol, 2019, 37(8): 907-915.
doi: 10.1038/s41587-019-0201-4 pmid: 31375807 |
| [33] |
Gan XC, Stegle O, Behr J, Steffen JG, Drewe P, Hildebrand KL, Lyngsoe R, Schultheiss SJ, Osborne EJ, Sreedharan VT, Kahles A, Bohnert R, Jean G, Derwent P, Kersey P, Belfield EJ, Harberd NP, Kemen E, Toomajian C, Kover PX, Clark RM, Ratsch G, Mott R. Multiple reference genomes and transcriptomes for Arabidopsis thaliana. Nature, 2011, 477(7365): 419-423.
doi: 10.1038/nature10414 |
| [34] |
Qin P, Lu HW, Du HL, Wang H, Chen WL, Chen Z, He Q, Ou SJ, Zhang HY, Li XZ, Li XX, Li Y, Liao Y, Gao Q, Tu B, Yuan H, Ma BT, Wang YP, Qian YW, Fan SJ, Li WT, Wang J, He M, Yin JJ, Li T, Jiang N, Chen XW, Liang CZ, Li SG. Pan-genome analysis of 33 genetically diverse rice accessions reveals hidden genomic variations. Cell, 2021, 184(13): 3542-3558.
doi: 10.1016/j.cell.2021.04.046 pmid: 34051138 |
| [35] |
Zhou Y, Zhang ZY, Bao ZG, Li HB, Lyu YQ, Zan YJ, Wu YY, Cheng L, Fang YH, Wu K, Zhang JZ, Lyu HJ, Lin T, Gao Q, Saha S, Mueller L, Fei ZJ, Städler T, Xu SZ, Zhang ZW, Speed D, Huang SW. Graph pangenome captures missing heritability and empowers tomato breeding. Nature, 2022, 606(7914): 527-534.
doi: 10.1038/s41586-022-04808-9 |
| [36] |
Huang Y, He JX, Xu YT, Zheng WK, Wang SH, Chen P, Zeng B, Yang SZ, Jiang XL, Liu ZS, Wang L, Wang X, Liu SJ, Lu ZH, Liu Z, Yu HW, Yue JQ, Gao JY, Zhou XY, Long CR, Zeng XL, Guo YJ, Zhang WF, Xie ZZ, Li CL, Ma ZC, Jiao WB, Zhang F, Larkin RM, Krueger RR, Smith MW, Ming R, Deng XX, Xu Q. Pangenome analysis provides insight into the evolution of the orange subfamily and a key gene for citric acid accumulation in citrus fruits. Nat Genet, 2023, 55(11): 1964-1975.
doi: 10.1038/s41588-023-01516-6 pmid: 37783780 |
| [37] |
Jin SK, Han ZG, Hu Y, Si ZF, Dai F, He L, Cheng Y, Li YQ, Zhao T, Fang L, Zhang TZ. Structural variation (SV)-based pan-genome and GWAS reveal the impacts of SVs on the speciation and diversification of allotetraploid cottons. Mol Plant, 2023, 16(4): 678-693.
doi: 10.1016/j.molp.2023.02.004 pmid: 36760124 |
| [38] |
Li HB, Wang SH, Chai S, Yang ZQ, Zhang QQ, Xin HJ, Xu YC, Lin SG, Chen XX, Yao ZW, Yang QY, Fei ZJ, Huang SW, Zhang ZH. Graph-based pan-genome reveals structural and sequence variations related to agronomic traits and domestication in cucumber. Nat Commun, 2022, 13(1): 682.
doi: 10.1038/s41467-022-28362-0 pmid: 35115520 |
| [39] |
Liu YC, Du HL, Li PC, Shen YT, Peng H, Liu SL, Zhou G-A, Zhang HK, Liu Z, Shi M, Huang XH, Li Y, Zhang M, Wang Z, Zhu BG, Han B, Liang CZ, Tian ZX. Pan-genome of wild and cultivated soybeans. Cell, 2020, 182(1): 162-176.
doi: S0092-8674(20)30618-8 pmid: 32553274 |
| [40] |
He Q, Tang S, Zhi H, Chen JF, Zhang J, Liang HK, Alam O, Li HB, Zhang H, Xing LH, Li XK, Zhang W, Wang HL, Shi JP, Du HL, Wu HP, Wang LW, Yang P, Xing L, Yan HS, Song ZQ, Liu JR, Wang HG, Tian X, Qiao ZJ, Feng GJ, Guo RF, Zhu WJ, Ren YM, Hao HB, Li MZ, Zhang AY, Guo EH, Yan F, Li QQ, Liu YL, Tian BH, Zhao XQ, Jia RL, Feng BL, Zhang JW, Wei JH, Lai JS, Jia GQ, Purugganan M, Diao XM. A graph-based genome and pan-genome variation of the model plant Setaria. Nat Genet, 2023, 55(7): 1232-1242.
doi: 10.1038/s41588-023-01423-w pmid: 37291196 |
| [41] |
Chen S, Wang PJ, Kong WL, Chai K, Zhang SC, Yu JX, Wang YB, Jiang MW, Lei WL, Chen X, Wang WL, Gao YY, Qu SY, Wang F, Wang YH, Zhang Q, Gu MY, Fang KX, Ma CL, Sun WJ, Ye NX, Wu HL, Zhang XT. Gene mining and genomics-assisted breeding empowered by the pangenome of tea plant Camellia sinensis. Nat Plants, 2023, 9(12): 1986-1999.
doi: 10.1038/s41477-023-01565-z pmid: 38012346 |
| [42] |
Zhao Q, Feng Q, Lu HY, Li Y, Wang AH, Tian QL, Zhan QL, Lu YQ, Zhang L, Huang T, Wang YC, Fan DL, Zhao Y, Wang ZQ, Zhou CC, Chen JY, Zhu CR, Li WJ, Weng QJ, Xu Q, Wang ZX, Wei XH, Han B, Huang XH. Pan-genome analysis highlights the extent of genomic variation in cultivated and wild rice. Nat Genet, 2018, 50(2): 278-284.
doi: 10.1038/s41588-018-0041-z pmid: 29335547 |
| [43] |
Song JM, Guan ZL, Hu JL, Guo CC, Yang ZQ, Wang S, Liu DX, Wang B, Lu SP, Zhou R, Xie WZ, Cheng YF, Zhang YT, Liu KD, Yang QY, Chen LL, Guo L. Eight high-quality genomes reveal pan-genome architecture and ecotype differentiation of Brassica napus. Nat Plants, 2020, 6(1): 34-45.
doi: 10.1038/s41477-019-0577-7 |
| [44] |
Shang LG, Li XX, He HY, Yuan QL, Song YN, Wei ZR, Lin H, Hu M, Zhao FL, Zhang C, Li YH, Gao HS, Wang TY, Liu XP, Zhang H, Zhang Y, Cao SM, Yu XM, Zhang BT, Zhang Y, Tan YQ, Qin M, Ai C, Yang YX, Zhang B, Hu ZQ, Wang HR, Lv Y, Wang YX, Ma J, Wang Q, Lu HW, Wu Z, Liu SL, Sun ZY, Zhang HL, Guo LB, Li ZC, Zhou YF, Li JY, Zhu ZF, Xiong GS, Ruan J, Qian Q. A super pan-genomic landscape of rice. Cell Res, 2022, 32(10): 878-896.
doi: 10.1038/s41422-022-00685-z pmid: 35821092 |
| [45] |
Alonge M, Wang XG, Benoit M, Soyk S, Pereira L, Zhang L, Suresh H, Ramakrishnan S, Maumus F, Ciren D, Levy Y, Harel TH, Shalev-Schlosser G, Amsellem Z, Razifard H, Caicedo AL, Tieman DM, Klee H, Kirsche M, Aganezov S, Ranallo-Benavidez TR, Lemmon ZH, Kim J, Robitaille G, Kramer M, Goodwin S, McCombie WR, Hutton S, Van Eck J, Gillis J, Eshed Y, Sedlazeck FJ, van der Knaap E, Schatz MC, Lippman ZB. Major impacts of widespread structural variation on gene expression and crop improvement in tomato. Cell, 2020, 182(1): 145-161.
doi: S0092-8674(20)30616-4 pmid: 32553272 |
| [46] |
Chen JF, Liu Y, Liu MX, Guo WL, Wang YQ, He Q, Chen WY, Liao Y, Zhang W, Gao YZ, Dong KJ, Ren RY, Yang TY, Zhang LY, Qi MY, Li ZG, Zhao M, Wang HG, Wang JJ, Qiao ZJ, Li HQ, Jiang YM, Liu GQ, Song XQ, Deng YR, Li H, Yan F, Dong Y, Li QQ, Li T, Yang WY, Cui JH, Wang HR, Zhou YF, Zhang XM, Jia GQ, Lu P, Zhi H, Tang S, Diao XM. Pangenome analysis reveals genomic variations associated with domestication traits in broomcorn millet. Nat Genet, 2023, 55(12): 2243-2254.
doi: 10.1038/s41588-023-01571-z |
| [47] |
Gijzen M, Weng CR, Kuflu K, Woodrow L, Yu KF, Poysa V. Soybean seed lustre phenotype and surface protein cosegregate and map to linkage group E. Genome, 2003, 46(4): 659-664.
doi: 10.1139/g03-047 pmid: 12897873 |
| [48] |
Jones CD, Begun DJ. Parallel evolution of chimeric fusion genes. Proc Natl Acad Sci USA, 2005, 102(32): 11373-11378.
pmid: 16076957 |
| [49] |
Watanabe S, Hideshima R, Xia ZJ, Tsubokura Y, Sato S, Nakamoto Y, Yamanaka N, Takahashi R, Ishimoto M, Anai T, Tabata S, Harada K.Map-based cloning of the gene associated with the soybean maturity locus E3. Genetics, 2009, 182(4): 1251-1262.
doi: 10.1534/genetics.108.098772 pmid: 19474204 |
| [50] |
Tsubokura Y, Watanabe S, Xia ZJ, Kanamori H, Yamagata H, Kaga A, Katayose Y, Abe J, Ishimoto M, Harada K. Natural variation in the genes responsible for maturity loci E1, E2, E3 and E4 in soybean. Ann Bot, 2014, 113(3): 429-441.
doi: 10.1093/aob/mct269 |
| [51] |
Lam HM, Xu X, Liu X, Chen WB, Yang GH, Wong FL, Li MW, He WM, Qin N, Wang B, Li J, Jian M, Wang J, Shao GH, Wang J, Sun SSM, Zhang GY. Resequencing of 31 wild and cultivated soybean genomes identifies patterns of genetic diversity and selection. Nat Genet, 2010, 42(12): 1053-1059.
doi: 10.1038/ng.715 |
| [52] |
Lu SJ, Zhao XH, Hu YL, Liu SL, Nan HY, Li XM, Fang C, Cao D, Shi XY, Kong LP, Su T, Zhang FG, Li SC, Wang Z, Yuan XH, Cober ER, Weller JL, Liu BH, Hou XL, Tian ZX, Kong FJ. Natural variation at the soybean J locus improves adaptation to the tropics and enhances yield. Nat Genet, 2017, 49(5): 773-779.
doi: 10.1038/ng.3819 |
| [53] |
Torkamaneh D, Laroche J, Tardivel A, O'Donoughue L, Cober E, Rajcan I, Belzile F. Comprehensive description of genomewide nucleotide and structural variation in short-season soya bean. Plant Biotechnol J, 2018, 16(3): 749-759.
doi: 10.1111/pbi.12825 pmid: 28869792 |
| [54] |
Zhou ZK, Jiang Y, Wang Z, Gou ZH, Lyu J, Li WY, Yu YJ, Shu LP, Zhao YJ, Ma YM, Fang C, Shen YT, Liu TF, Li CC, Li Q, Wu M, Wang M, Wu YS, Dong Y, Wan WT, Wang X, Ding ZL, Gao YD, Xiang H, Zhu BG, Lee SH, Wang W, Tian ZX. Resequencing 302 wild and cultivated accessions identifies genes related to domestication and improvement in soybean. Nat Biotechnol, 2015, 33(4): 408-414.
doi: 10.1038/nbt.3096 pmid: 25643055 |
| [55] |
Woodworth CM. Inheritance of cotyledon, seed-coat, hilum and pubescence colors in soy-beans. Genetics, 1921, 6(6): 487-553.
doi: 10.1093/genetics/6.6.487 pmid: 17245974 |
| [56] |
Tuteja JH, Clough SJ, Chan WC, Vodkin LO. Tissue- specific gene silencing mediated by a naturally occurring chalcone synthase gene cluster in Glycine max. Plant Cell, 2004, 16(4): 819-835.
doi: 10.1105/tpc.021352 |
| [57] |
Tuteja JH, Zabala G, Varala K, Hudson M, Vodkin LO. Endogenous, tissue-specific short interfering RNAs silence the chalcone synthase gene family in Glycine max seed coats. Plant Cell, 2009, 21(10): 3063-3077.
doi: 10.1105/tpc.109.069856 |
| [58] |
Wang CS, Todd JJ, Vodkin LO. Chalcone synthase mRNA and activity are reduced in yellow soybean seed coats with dominant I alleles. Plant Physiol, 1994, 105(2): 739-748.
doi: 10.1104/pp.105.2.739 pmid: 8066134 |
| [59] |
Xie M, Chung CYL, Li MW, Wong FL, Wang X, Liu AL, Wang ZL, Leung AKY, Wong TH, Tong SW, Xiao ZX, Fan KJ, Ng MS, Qi XP, Yang LF, Deng TQ, He LJ, Chen L, Fu AS, Ding Q, He JX, Chung G, Isobe S, Tanabata T, Valliyodan B, Nguyen HT, Cannon SB, Foyer CH, Chan TF, Lam HM. A reference-grade wild soybean genome. Nat Commun, 2019, 10(1): 1216.
doi: 10.1038/s41467-019-09142-9 pmid: 30872580 |
| [60] |
Lin S, Cianzio S, Shoemaker R. Mapping genetic loci for iron deficiency chlorosis in soybean. Mol Breeding, 1997, 3(3): 219-229.
doi: 10.1023/A:1009637320805 |
| [61] |
Wicker T, Sabot F, Hua-Van A, Bennetzen JL, Capy P, Chalhoub B, Flavell A, Leroy P, Morgante M, Panaud O, Paux E, SanMiguel P, Schulman AH. A unified classification system for eukaryotic transposable elements. Nat Rev Genet, 2007, 8(12): 973-982.
doi: 10.1038/nrg2165 pmid: 17984973 |
| [62] |
Zhuang YB, Wang XT, Li XC, Hu JM, Fan LC, Landis JB, Cannon SB, Grimwood J, Schmutz J, Jackson SA, Doyle JJ, Zhang XS, Zhang DJ, Ma JX. Phylogenomics of the genus Glycine sheds light on polyploid evolution and life-strategy transition. Nat Plants, 2022, 8(3): 233-244.
doi: 10.1038/s41477-022-01102-4 |
| [63] |
Wendel JF. The wondrous cycles of polyploidy in plants. Am J Bot, 2015, 102(11): 1753-1756.
doi: 10.3732/ajb.1500320 pmid: 26451037 |
| [64] |
Zhao MX, Zhang B, Lisch D, Ma JX. Patterns and consequences of subgenome differentiation provide insights into the nature of paleopolyploidy in plants. Plant Cell, 2017, 29(12): 2974-2994.
doi: 10.1105/tpc.17.00595 |
| [65] |
Ameur A. Goodbye reference, hello genome graphs. Nat Biotechnol, 2019, 37(8): 866-868.
doi: 10.1038/s41587-019-0199-7 pmid: 31375808 |
| [66] |
Bayer PE, Golicz AA, Scheben A, Batley J, Edwards D. Plant pan-genomes are the new reference. Nature Plants, 2020, 6: 914-920.
doi: 10.1038/s41477-020-0733-0 pmid: 32690893 |
| [67] |
Lappalainen T, Scott AJ, Brandt M, Hall IM. Genomic analysis in the age of human genome sequencing. Cell, 2019, 177(1): 70-84.
doi: S0092-8674(19)30215-6 pmid: 30901550 |
| [68] |
Huang XH, Huang SW, Han B, Li JY. The integrated genomics of crop domestication and breeding. Cell, 2022, 185(15): 2828-2839.
doi: 10.1016/j.cell.2022.04.036 pmid: 35643084 |
| [69] |
Shi JP, Tian ZX, Lai JS, Huang XH. Plant pan-genomics and its applications. Mol Plant, 2023, 16(1): 168-186.
doi: 10.1016/j.molp.2022.12.009 |
| [70] |
Lei L, Goltsman E, Goodstein D, Wu GA, Rokhsar DS, Vogel JP. Plant pan-genomics comes of age. Annu Rev Plant Biol, 2021, 72: 411-435.
doi: 10.1146/annurev-arplant-080720-105454 pmid: 33848428 |
| [71] |
Yu H, Lin T, Meng XB, Du HL, Zhang JK, Liu GF, Chen MJ, Jing YH, Kou LQ, Li XX, Gao Q, Liang Y, Liu XD, Fan ZL, Liang YT, Cheng ZK, Chen MS, Tian ZX, Wang YH, Chu CC, Zuo JR, Wan JM, Qian Q, Han B, Zuccolo A, Wing RA, Gao CX, Liang CZ, Li JY. A route to de novo domestication of wild allotetraploid rice. Cell, 2021, 184(5): 1156-1170. e14.
doi: 10.1016/j.cell.2021.01.013 |
| [72] |
Lewin HA, Robinson GE, Kress WJ, Baker WJ, Coddington JA, Crandall KA, Durbin R, Edwards SV, Forest F, Gilbert MTP, Goldstein MM, Grigoriev IV, Hackett KJ, Haussler D, Jarvis ED, Johnson WE, Patrinos A, Richards S, Castilla-Rubio JC, van Sluys MA, Soltis PS, Xu X, Yang HM. Earth BioGenome Project: sequencing life for the future of life. Proc Natl Acad Sci USA, 2018, 115(17): 4325-4333.
doi: 10.1073/pnas.1720115115 pmid: 29686065 |
| [73] |
Cheng S, Melkonian M, Smith SA, Brockington SF, Archibald JM, Delaux PM, Li F, Melkonian B, Mavrodiev EV, Sun WJ, Fu Y, Yang HM, Soltis DE, Graham SW, Soltis PS, Liu X, Xu X, Wong GKS. 10KP: a phylodiverse genome sequencing plan. GigaScience, 2018, 7(3): 1-9.
doi: 10.1093/gigascience/giy013 pmid: 29618049 |
| [74] | Liu YC, Zhang Y, Liu XN, Shen YT, Tian DM, Yang XY, Liu SL, Ni LB, Zhang Z, Song SH, Tian ZX. SoyOmics: a deeply integrated database on soybean multi-omics. Mol Plant, 2023, 16(5): 794-797. |
| [75] |
Han LQ, Zhong WS, Qian J, Jin ML, Tian P, Zhu WC, Zhang HW, Sun YH, Feng JW, Liu XG, Chen G, Farid B, Li RN, Xiong ZM, Tian ZH, Li J, Luo Z, Du DX, Chen SJ, Jin QX, Li JX, Li Z, Liang Y, Jin XM, Peng Y, Zheng C, Ye XN, Yin YJ, Chen H, Li WF, Chen LL, Li Q, Yan JB, Yang F, Li L. A multi-omics integrative network map of maize. Nat Genet, 2023, 55(1): 144-153.
doi: 10.1038/s41588-022-01262-1 pmid: 36581701 |
| [76] |
Zhou P, Silverstein KAT, Ramaraj T, Guhlin J, Denny R, Liu JQ, Farmer AD, Steele KP, Stupar RM, Miller JR, Tiffin P, Mudge J, Young ND. Exploring structural variation and gene family architecture with De novo assemblies of 15 Medicago genomes. BMC Genomics, 2017, 18(1): 261.
doi: 10.1186/s12864-017-3654-1 |
| [77] |
Ou LJ, Li D, Lv JH, Chen WC, Zhang ZQ, Li XF, Yang BZ, Zhou SD, Yang S, Li WG, Gao HZ, Zeng Q, Yu HY, Ouyang B, Li F, Liu F, Zheng JY, Liu YH, Wang J, Wang BB, Dai XZ, Ma YQ, Zou XX. Pan-genome of cultivated pepper (Capsicum) and its use in gene presence-absence variation analyses. New Phytol, 2018, 220(2): 360-363.
doi: 10.1111/nph.15413 pmid: 30129229 |
| [78] |
Yu JY, Golicz AA, Lu K, Dossa K, Zhang YX, Chen JF, Wang LH, You J, Fan DD, Edwards D, Zhang XR. Insight into the evolution and functional characteristics of the pan-genome assembly from sesame landraces and modern cultivars. Plant Biotechnol J, 2019, 17(5): 881-892.
doi: 10.1111/pbi.13022 pmid: 30315621 |
| [79] | Jayakodi M, Padmarasu S, Haberer G, Bonthala VS, Gundlach H, Monat C, Lux T, Kamal N, Lang D, Himmelbach A, Ens J, Zhang XQ, Angessa TT, Zhou GF, Tan C, Hill C, Wang PH, Schreiber M, Boston LB, Plott C, Jenkins J, Guo Y, Fiebig A, Budak H, Xu DD, Zhang J, Wang CC, Grimwood J, Schmutz J, Guo GG, Zhang GP, Mochida K, Hirayama T, Sato K, Chalmers KJ, Langridge P, Waugh R, Pozniak CJ, Scholz U, Mayer KFX, Spannagl M, Li C, Mascher M, Stein N. The barley pan-genome reveals the hidden legacy of mutation breeding. Nature, 2020, 588(7837): 284-289. |
| [80] |
Varshney RK, Roorkiwal M, Sun S, Bajaj P, Chitikineni A, Thudi M, Singh NP, Du X, Upadhyaya HD, Khan AW, Wang Y, Garg V, Fan Gy, Cowling WA, Crossa J, Gentzbittel L, Voss-Fels KP, Valluri VK, Sinha P, Singh VK, Ben C, Rathore A, Punna R, Singh MK, Tar'an B, Bharadwaj C, Yasin M, Pithia MS, Singh S, Soren KR, Kudapa H, Jarquín D, Cubry P, Hickey LT, Dixit GP, Thuillet AC, Hamwieh A, Kumar S, Deokar AA, Chaturvedi SK, Francis A, Howard R, Chattopadhyay D, Edwards D, Lyons E, Vigouroux Y, Hayes BJ, von Wettberg E, Datta SK, Yang HM, Nguyen HT, Wang J, Siddique KHM, Mohapatra T, Bennetzen JL, Xu X, Liu X. A chickpea genetic variation map based on the sequencing of 3,366 genomes. Nature, 2021, 599(7886): 622-627.
doi: 10.1038/s41586-021-04066-1 |
| [81] |
Li JY, Yuan DJ, Wang PC, Wang QQ, Sun ML, Liu ZP, Si H, Xu ZP, Ma YZ, Zhang BY, Pei LL, Tu LL, Zhu LF, Chen LL, Lindsey K, Zhang XL, Jin SX, Wang MJ. Cotton pan-genome retrieves the lost sequences and genes during domestication and selection. Genome Biol, 2021, 22(1): 119.
doi: 10.1186/s13059-021-02351-w pmid: 33892774 |
| [82] |
Tao YF, Luo H, Xu JB, Cruickshank A, Zhao XR, Teng F, Hathorn A, Wu XY, Liu YM, Shatte T, Jordan D, Jing HC, Mace E. Extensive variation within the pan-genome of cultivated and wild sorghum. Nat Plants, 2021, 7(6): 766-773.
doi: 10.1038/s41477-021-00925-x pmid: 34017083 |
| [83] | Hufford MB, Seetharam AS, Woodhouse MR, Chougule KM, Ou SJ, Liu JN, Ricci WA, Guo TT, Olson A, Qiu YJ, Della Coletta R, Tittes S, Hudson AI, Marand AP, Wei SR, Lu ZY, Wang B, Tello-Ruiz MK, Piri RD, Wang N, Kim DW, Zeng YB, O'Connor CH, Li XR, Gilbert AM, Baggs E, Krasileva KV, Portwood JL, 2nd, Cannon EKS, Andorf CM, Manchanda N, Snodgrass SJ, Hufnagel DE, Jiang QH, Pedersen S, Syring ML, Kudrna DA, Llaca V, Fengler K, Schmitz RJ, Ross-Ibarra J, Yu JM, Gent JI, Hirsch CN, Ware D, Dawe RK. De novo assembly, annotation, and comparative analysis of 26 diverse maize genomes. Science, 2021, 373(6555): 655-662. |
| [84] |
Zhang XH, Liu TJ, Wang JL, Wang P, Qiu Y, Zhao W, Pang S, Li XM, Wang HP, Song JP, Zhang WL, Yang WL, Sun YY, Li XX. Pan-genome of Raphanus highlights genetic variation and introgression among domesticated, wild, and weedy radishes. Mol Plant, 2021, 14(12): 2032-2055.
doi: 10.1016/j.molp.2021.08.005 |
| [85] |
Li N, He Q, Wang J, Wang BK, Zhao JT, Huang SY, Yang T, Tang YP, Yang SB, Aisimutuola P, Xu RQ, Hu JH, Jia CP, Ma K, Li ZQ, Jiang FL, Gao J, Lan HY, Zhou YF, Zhang XY, Huang SW, Fei ZJ, Wang H, Li HB, Yu QH. Super-pangenome analyses highlight genomic diversity and structural variation across wild and cultivated tomato species. Nat Genet, 2023, 55(5): 852-860.
doi: 10.1038/s41588-023-01340-y pmid: 37024581 |
| [86] |
Wang MJ, Li JY, Qi ZY, Long YX, Pei LL, Huang XH, Grover CE, Du XM, Xia CJ, Wang PC, Liu ZP, You JQ, Tian XH, Ma YZ, Wang RP, Chen XY, He X, Fang DD, Sun YQ, Tu LL, Jin SX, Zhu LF, Wendel JF, Zhang XL. Genomic innovation and regulatory rewiring during evolution of the cotton genus Gossypium. Nat Genet, 2022, 54(12): 1959-1971.
doi: 10.1038/s41588-022-01237-2 pmid: 36474047 |
| [87] |
Tang D, Jia YX, Zhang JZ, Li HB, Cheng L, Wang P, Bao ZG, Liu ZH, Feng SS, Zhu XJ, Li DW, Zhu GT, Wang HR, Zhou Y, Zhou YF, Bryan GJ, Buell CR, Zhang CZ, Huang SW. Genome evolution and diversity of wild and cultivated potatoes. Nature, 2022, 606(7914): 535-541.
doi: 10.1038/s41586-022-04822-x |
| [88] |
Wang BB, Hou M, Shi JP, Ku LX, Song W, Li CH, Ning Q, Li X, Li CY, Zhao BB, Zhang RY, Xu H, Bai ZJ, Xia ZC, Wang H, Kong DX, Wei HB, Jing YF, Dai ZY, Wang HHL, Zhu XY, Li CH, Sun X, Wang SS, Yao W, Hou GG, Qi Z, Dai H, Li XM, Zheng HK, Zhang ZX, Li Y, Wang TY, Jiang TJ, Wan ZM, Chen YH, Zhao JR, Lai JS, Wang HY. De novo genome assembly and analyses of 12 founder inbred lines provide insights into maize heterosis. Nat Genet, 2023, 55(2): 312-323.
doi: 10.1038/s41588-022-01283-w |
| [1] | 杨漫宇, 姚方杰, 杨足君, 杨恩年. 六倍体小黑麦×六倍体小麦杂交后代中染色体遗传与结构变异鉴定[J]. 遗传, 2024, 46(1): 63-77. |
| [2] | 赵洪, 薛勇彪. 显花植物自交不亲和性的分子与演化机制[J]. 遗传, 2024, 46(1): 3-17. |
| [3] | 田璐妍, 黄小珍. 植物开花调控中蛋白质相分离机制在从头驯化中的应用价值[J]. 遗传, 2023, 45(9): 754-764. |
| [4] | 廉小平, 黄光福, 张玉娇, 张静, 胡凤益, 张石来. 长雄野生稻有利基因的发掘与利用[J]. 遗传, 2023, 45(9): 765-780. |
| [5] | 简六梅, 肖英杰, 严建兵. 从头驯化:作物品种设计与培育的新方向[J]. 遗传, 2023, 45(9): 741-753. |
| [6] | 赖笔威, 陈磊, 芦思佳. 大豆光周期适应性研究进展[J]. 遗传, 2023, 45(9): 793-800. |
| [7] | 邢超凡, 王闽涛, 王磊, 申欣. 两侧对称动物左右不对称发生机制研究进展[J]. 遗传, 2023, 45(6): 488-500. |
| [8] | 郑泽权, 付巧妹, 刘逸宸. 应用古DNA技术探究发酵微生物的适应、演化和驯化历史[J]. 遗传, 2022, 44(5): 414-423. |
| [9] | 付孟, 李艳. 家马的起源历史与品种驯化特征[J]. 遗传, 2022, 44(3): 216-229. |
| [10] | 高珊珊, 李金良, 杨佳妮, 周通, 刘瑞, 王晓萍, 于黎. 哺乳动物滑翔和飞行性状适应性演化研究进展[J]. 遗传, 2022, 44(1): 46-58. |
| [11] | 文钟灵, 杨旻恺, 陈星雨, 郝晨宇, 任然, 储淑娟, 韩洪苇, 林红燕, 陆桂华, 戚金亮, 杨永华. 酸铝胁迫土壤中耐铝大豆根际不同部位细菌群落结构、功能及其对促生菌富集作用的研究[J]. 遗传, 2021, 43(5): 487-500. |
| [12] | 文子龙, 赵毅强. 群体遗传学下动物驯化研究进展[J]. 遗传, 2021, 43(3): 226-239. |
| [13] | 边培培, 张禹, 姜雨. 泛基因组:高质量参考基因组的新标准[J]. 遗传, 2021, 43(11): 1023-1037. |
| [14] | 孙小媛, 王一帆, 王韫慧, 蔺佳雨, 李金红, 丘远涛, 方小龙, 孔凡江, 李美娜. 大豆细胞核雄性不育基因研究进展[J]. 遗传, 2021, 43(1): 52-65. |
| [15] | 毛卓卓, 宫宇, 史贵霞, 李亚丽, 喻德跃, 黄方. 大豆E2泛素结合酶基因GmUBC1的克隆及在拟南芥中的异源表达[J]. 遗传, 2020, 42(8): 788-798. |
| 阅读次数 | ||||||
|
全文 |
|
|||||
|
摘要 |
|
|||||

www.chinagene.cn
备案号:京ICP备09063187号-4
总访问:,今日访问:,当前在线:
